- Стоит ли вообще тратить на это время?
- Файловый вариант информационной базы
- SQL-вариант информационной базы
- Журнал транзакций (Transaction log, TLog)
- Резервные копии журнала транзакций (Transaction log backup, TLog backup)
- Полные резервные копии базы данных (Full database backup, Full backup)
- Разностные резервные копии (Differential backup, Diff backup)
- Резервное копирование заключительного фрагмента журнала транзакций
- Full recovery model (работает только с регламентными заданиями и под контролем администраторов)
- Перейдем к практике
- Реальный план обслуживания
- Параллелизм и ограничения
- Странное расписание
- Переход через полночь
- Зачем создавать в одно и то же время полный бэкап и бэкап ЖТ
- Вычисляемые параметры
- Почему две задачи серые?
- Запрет задач и моделирование результата
- Реализация условия ((A or B) and C) для ограничений задачи или фиктивные задачи, которые совсем не фиктивные
- Асинхронность выполнения
- Что это такое?
- Параллельно или последовательно
- Параллелизм внутри стандартных задач Backup Database и Check Database Integrity и интерпретация результата их выполнения
- Расписание задач обслуживания (ключевой вопрос, часто считающийся второстепенным)
- Периодичность TLog backup
- Взаимосвязанная периодичность Full backup и Diff backup
- Заблуждения экспертов
- Особенности восстановления – как не потерять данные
Традиционно, пользователи 1С делятся на две категории: тех, кто делает резервные копии*, и тех, кто начнет их делать. Чтобы не учиться на собственных ошибках, давайте начнем делать резервное копирование прямо сейчас.
*Если вы уже делаете резервные копии, эта статья все равно окажется вам полезной, поскольку многое из того, что можно найти и прочитать на тему резервного копирования в Интернете, ошибочно и весьма опасно для сохранности ваших данных. Если вы ИТ-специалист — переходите к чтению раздела «Резервное копирование информационной базы 1С средствами SQL».
Стоит ли вообще тратить на это время?
Разве в наше время информационная база 1С может как-то сломаться? Ломается все: чайники и самолеты, ножка от табуретки и электронный микроскоп. Трудно сломать только что-то очень простое, например, чугунный шар. Но информационная база 1С – сложный объект и функционирует в сложной технологической среде. Рано или поздно что-то произойдет, сначала совсем незначительное, а далее «открутившийся винтик» вызовет каскадную реакцию отказов ПО и оборудования, которая в итоге закончится крупными неприятностями и потерей информационной базы.
Файловый вариант информационной базы
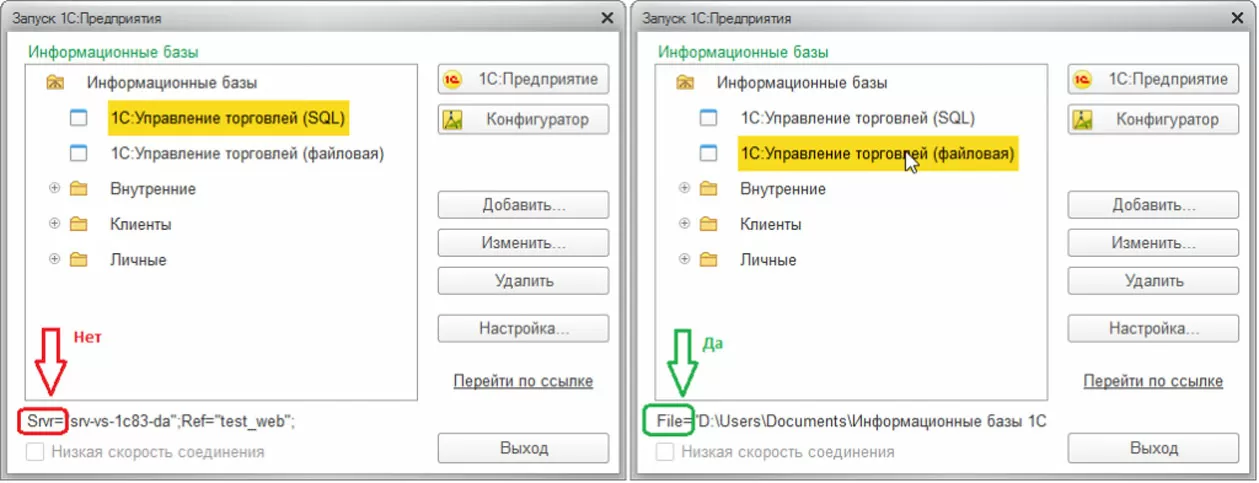
Начнем с самого простого примера. В небольшой организации работает конфигурация 1С с файловой информационной базой, которую обслуживает приходящий системный администратор, который вероятно все настроил. Но! Отсутствие сообщений «Не настроено резервное копирование» вовсе не означает, что теперь оно настроено. Это может означать также, что данное сообщение просто не показывается. Поэтому, взяв на себя ответственность за надежность и сохранность результатов своего труда, для начала убедимся, что информационная база именно файловая. Как это сделать – наглядно показано на иллюстрации ниже. Если вместо File= написано Srv=, это SQL-база и для настройки резервного копирования обратитесь к вашему администратору баз данных. Если база файловая, можно воспользоваться ручным или автоматическим копированием.
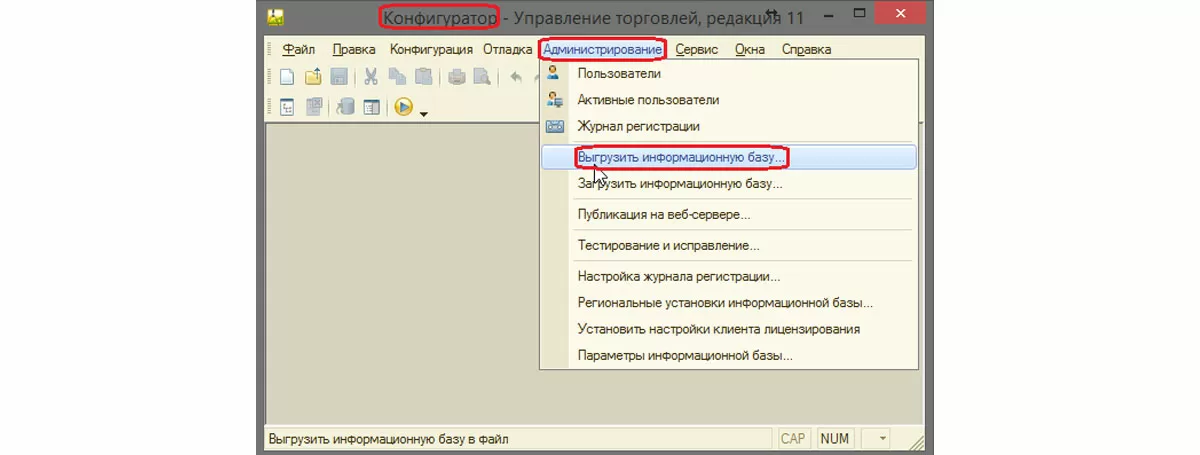
Ручной способ – создайте резервную копию, как показано на иллюстрации. Перед выгрузкой все пользователи должны завершить работу с информационной базой. Выгрузка создает один файл резервной копии с расширением DT, в котором будет почти все (об этом – далее), что есть в данный момент в информационной базе, и не будет того, что введется после. Дайте осмысленное имя файлу (например, «Резервная копия Управления торговлей на 2017-10-31») и выберите для его сохранения специальную папку (например, папка «Резервные копии» в папке «Мои документы»). Используя этот файл, вы можете впоследствии восстановить информационную базу до состояния, которое предшествовало выгрузке. Для восстановления надо использовать операцию «Загрузить информационную базу».
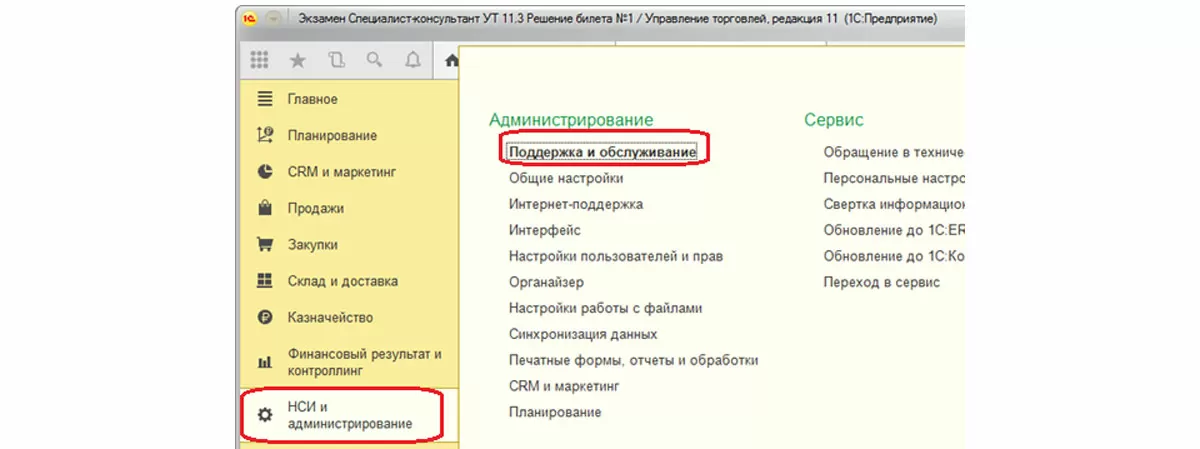
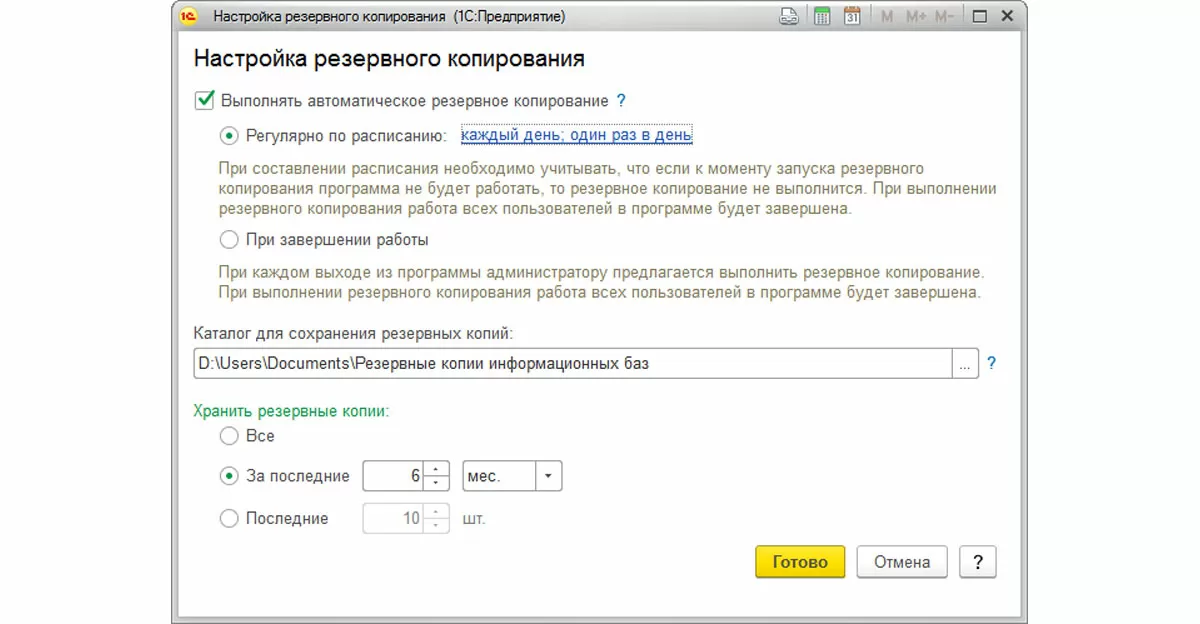
Автоматический способ. Расположение ссылки «настройка резервного копирования» может отличаться в разных конфигурациях и редакциях 1С.
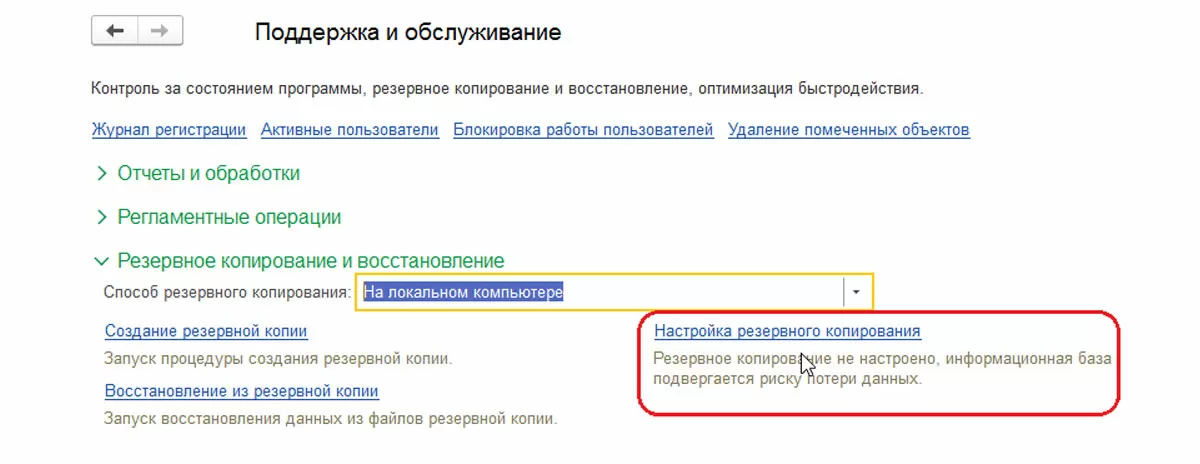
Типичная настройка резервного копирования показана на иллюстрации. Такая настройка предполагает, что пользователь с правами администратора оставляет открытой программу в конце рабочего дня (иначе резервное копирование не выполнится), а все остальные пользователи программу закрывают. Альтернативный вариант – выполнять резервное копирование при завершении работы (будет запрошено подтверждение необходимости резервного копирования).
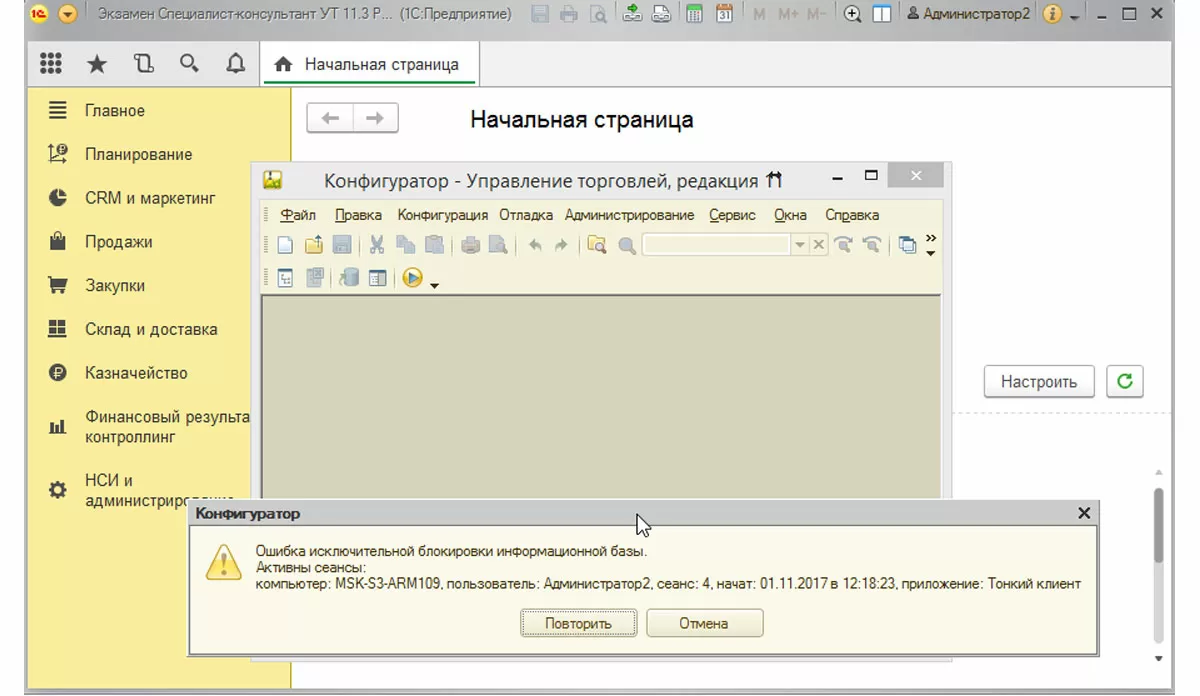
При наступлении времени резервного копирования в первом случае или при завершении работы последнего пользователя с административными правами во втором, системой будет установлена блокировка информационной базы с завершением работы всех пользователей. Это сложный процесс, который может не сработать, что повлечет ошибку резервного копирования (на иллюстрации ниже). Об этом вы можете прочитать специальную статью на нашем сайте.
Поэтому ограничиться единовременной настройкой автоматического резервного копирования не получится, за созданием резервных копий все равно придется регулярно следить.
А сейчас некоторые вопросы, которые не рассмотрены в популярных статьях на тему резервного копирования.
- Все ли попадет в резервную копию?
Нет. Вы можете потерять или испортить историю работы (кто и когда входил и выходил ли из программы), историю изменений объектов (кто и когда менял данные). Эта информация хранится вне информационной базы, ее хранение и правильное восстановление требует специальных действий. Вы можете потерять или испортить прикрепленные к объектам 1С-файлы (сканы документов, фотографии и т.д.). В зависимости от настроек эти данные могут храниться внутри или вне информационной базы, в последнем случае их сохранение и правильное восстановление также требует специальных действий. В резервной копии также не сохранятся настройки управляемых форм, сделанные пользователями.
- Можно ли делать резервную копию в процессе работы?
Стандартный механизм сначала пытается завершить работу пользователей. Однако это не всегда удается, поэтому операция резервного копирования может быть выполнена и при работающих пользователях. В этом случае предполагается, что эти пользователи не производят модификацию данных. Но если это не так, гарантия корректности резервной копии отсутствует. То есть ответ на этот вопрос – нет, нельзя.
- Как часто надо делать резервные копии?
Зависит от интенсивности ввода данных и критичности их потери. Для небольшого предприятия с одним-двумя пользователями 1С рекомендуем делать это минимум ежедневно. При 20 пользователях рекомендуем создавать одну ночную резервную копию и несколько резервных копий в ходе рабочего дня. Как вы помните, это повлечет временный технологический перерыв в работе пользователей.
- У нас были случаи потери данных, и мы бы хотели перейти на SQL-вариант информационной базы, но это очень дорого…
Возможно, вам подойдет бесплатный вариант MS SQL. Обратитесь к нам за консультацией.
SQL-вариант информационной базы
Данная часть статьи будет интересна специалистам и тем, кто еще только собирается им стать.
Сразу уточним, что избежать задачи резервного копирования нельзя. Ни репликация, ни абсолютно надежная аппаратура не защитит от случайного или злонамеренного повреждения данных на уровне приложения (ошибочное закрытие месяца, неверная работа плохо отлаженной обработки массового изменения данных и т.п.). Данные в этом случае надежно хранятся, но они неверны, а резервные копии отсутствуют, поэтому откат назад невозможен. На практике приходится восстанавливать информационную базу 1С из-за повреждения данных гораздо чаще, чем можно себе представить.
С точки зрения пользователя, живущего в понятийном пространстве файловых баз, у нас есть точки восстановления в виде бэкапов информационной базы, разделенные по времени частотой резервного копирования: если мы делаем копии раз в сутки, то в случае восстановления потеряем изменения, сделанные в базе максимум за сутки или меньше. Но в среде SQL server и способ хранения/изменения данных, и технологии резервного копирования предусматривают «бесконечное» количество точек, сливающихся в одну непрерывную прямую восстановления. Это означает возможность отката на точку, непосредственно предшествующую моменту сбоя или при необходимости на любой момент времени назад. На языке пользователя, это равнозначно созданию резервных копий раз в секунду и менее того.
Дело в том, что резервное копирование в среде SQL – это не последовательность нажатий кнопок, а комплекс регулярных мероприятий над сложно устроенными объектами. И этот комплекс создается в весьма сложной среде.
Чтобы понять «как все работает», мы еще раз обозначим цель наших действий – полное резервирование данных вплоть до секунды, предшествующей сбою (или моменту внесения нежелательных изменений) и возможность отката назад на произвольный момент времени с точностью до секунды.
Неужели так важно восстановление данных с точностью до секунды?
Это важно для фронт-офисных систем или в случае, когда предприятие достигает определенного масштаба. Поясним это утверждение, задав несколько наводящих вопросов. Легко ли организовать повторный ввод данных в филиальной сети, разбросанной по 10 регионам с разными часовыми поясами и имеющей несколько тысяч сотрудников? Как проконтролировать его правильность? Допустим, можно взять накладную и повторно ввести с нее данные. А как выполнить повторный ввод данных, которые поступали в систему при взаимодействии с аппаратурой (фискальные регистраторы, банковские терминалы) или со сторонними информационными системами (онлайн-кредит, процессинг скидочных карт единой партнерской сети), при участии большого количества людей (системы учета рабочего времени по отпечатку пальца)? Где взять источник информации для повторного ввода, если нет никаких документов, а все действия фиксируются безбумажным способом (учет питания в корпоративной столовой по карте сотрудника)?
Как получить копию базы со всеми данными, которые находились в системе «за секунду до взрыва»
Журнал транзакций (Transaction log, TLog)
Необходимо записывать в журнале все действия, которые мы собираемся произвести с базой данных, плюс их точное время (до микросекунд), и только затем выполнять их. Имея такой журнал (хранящийся на очень надежном и быстром носителе, обязательно отдельно от самой базы), мы могли бы повторить все операции с момента начала существования базы данных до произвольного момента восстановления с точностью до микросекунды. Но у ведения журнала транзакций есть два недостатка: через некоторое время с ростом базы TLog будет занимать очень много места (т.к. он непрерывно растет), а восстановление от «нулевого» момента времени будет выполняться очень долго.
Резервные копии журнала транзакций (Transaction log backup, TLog backup)
Образно выражаясь, мы будем регулярно забирать из журнала все листы и относить их в соседнюю комнату (назовем изъятые листы TLog backup), а в сам журнал класть пачку новых чистых листов, чтобы было, куда записывать новые действия с базой. Технически это выполняется так: снимается копия с файла TLog и записывается на архивный диск, после чего все записи в TLog «стираются» (помечаются как свободные, размер файла журнала не меняется), на «стертом» месте пишется информация о новых транзакциях. Очень важно понимать – каждая вырванная пачка листов, хоть и называется в устоявшейся терминологии Transaction Log backup, является единственным носителем информации о действиях с базой за этот период, а в самом журнале этой информации теперь нет. Поэтому потеря даже одного «вырванного листа» пока абсолютно недопустима, а термин TLog backup коварно маскирует сущность и назначение данной информации. Запомните – это не бэкап! Мы разбили журнал на множество файлов и информация в каждом из них нигде не продублирована. Но термин Transaction Log Backup общепринят, поэтому и дальше мы будем использовать именно его.
Теперь TLog бесконечно не растет, но возникает регламентная задача – резервное копирование TLog по расписанию.
Полные резервные копии базы данных (Full database backup, Full backup)
Если периодически делать копии всей базы данных, то для восстановления можно будет взять наиболее подходящую по времени копию и повторить не все операции с нулевого момента времени, а только операции с момента создания этой копии до момента восстановления (как говорят, «взять Full backup и накатить на него TLog»). Это значительно сокращает время восстановления, особенно если база существует уже лет 5. Помимо этого, теперь у нас появилась возможность удалять старые Full backup и TLog backup. На самом деле, откат назад с точностью до секунды зачастую может быть необходим только на коротком временном периоде (например, два месяца назад от текущего момента для расследования каких-то инцидентов или для восстановления базы за секунду до трагического внесения нежелательных изменений). В течение этого периода мы и будем хранить непрерывную цепочку TLog backup. За пределами этого периода можно хранить лишь точки восстановления в виде Full backup (и то не все, а например, только точки на первые числа месяца). TLog backup за пределами периода можно теперь удалять вообще (очевидно, что их выборочное удаление и выборочное хранение за пределами периода совершенно бессмысленно из-за нарушения непрерывности цепочки TLog). Так или иначе, возникает регламентная задача интеллектуального удаления.
Здесь возникает следующая проблема. Представим базу данных с большим количеством пользователей и высокой интенсивностью изменений. Условно – 33% времени тратится на запись и 67% на чтение, простоев нет. Когда мы будем восстанавливать базу, мы можем писать почти 100% времени, т.е. в три раза быстрее. Значит, мы можем три часа работы с базой восстановить по журналу за час. И этот час – максимальное время простоя на восстановление, на которое согласен бизнес. Допустим, Full backup делается раз в сутки. Если сбой произошел через 21 час от этого момента – нам придется потратить на восстановление по журналу 7 часов, что уже абсолютно неприемлемо. Значит, Full backup надо делать 1 раз в 3 часа? Увы, не всегда это возможно: базы бывают настолько большими (сотни гигабайт и даже терабайты), что за такое время Full backup создать просто невозможно. К тому же частое создание Full backup в рабочее время дает дополнительную нагрузку и замедляет работу пользователей, да и хранить такое количество данных весьма накладно. Но в принципе достаточно и того, что отсутствие возможности создать Full backup за приемлемое время полностью ставит крест на нашей технологии резервного копирования.
Разностные резервные копии (Differential backup, Diff backup)
Мы можем придумать специальную структуру хранения данных с непрерывно возрастающей нумерацией транзакций и другими хитростями, позволяющими легко понять разницу между двумя состояниями базы данных (от сих и до сих – уже было, все что далее – уже новое). Это позволит в резервной копии базы данных сохранить не все данные, а лишь отличия текущего Full backup от предыдущего Full backup. Процедура получения очередной полной копии будет простая: надо взять Full backup и накатить на него Diff backup. Вместо сохранения одного терабайта данных в Full backup мы сохранили в Diff backup всего десяток мегабайт и получили возможность делать это довольно часто – например, раз в полчаса. Но надо следить, чтобы была в наличии полная резервная копия, иначе разностная бесполезна.
В этом месте очень удачно можно сравнить дифференциальный бэкап и бэкап журнала транзакций, закрепив полученную информацию. Если не делать полную копию – размер дифференциальных бэкапов будет монотонно увеличиваться, т.к. будет накапливаться все больше и больше отличий от полной копии – и так до создания очередного полного бэкапа. Размеры очередных бэкапов журнала транзакций не будут иметь такой тенденции, их размер определяется количеством произведенных действий с базой за период. Обычно их размер колеблется вокруг некоего среднего значения, но в отдельные периоды (при выполнении операций массового изменения данных, при всплеске активности пользователей и т.д.) может очень сильно отличаться от среднего.
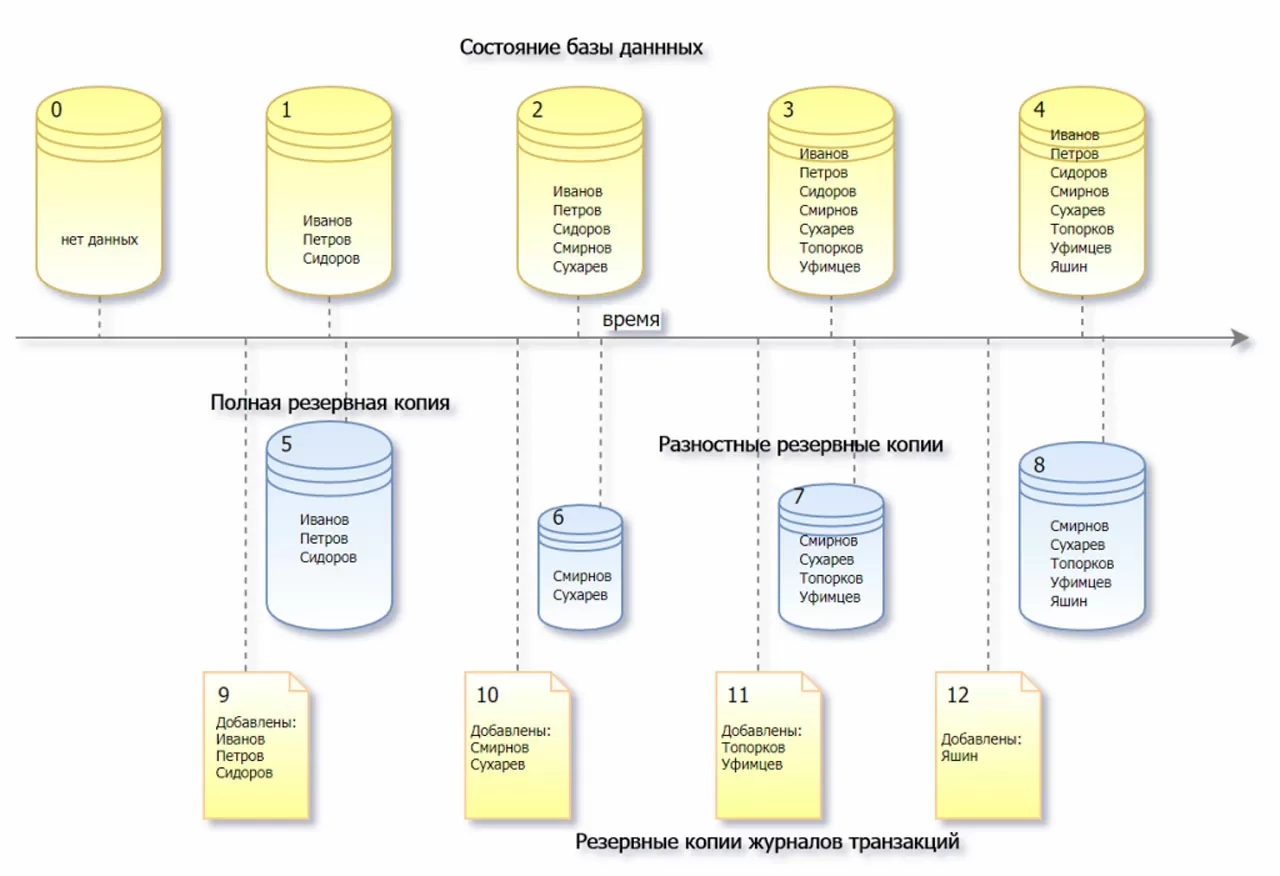
На иллюстрации ниже с некоторой долей условности изображена наша система резервного копирования. Первый ряд объектов отображает состояние базы данных, в которую периодически добавляются записи. Второй отображает одну полную резервную копию и три разностных. Третий ряд отображает содержимое резервных копий журнала транзакций. Каждый элемент пронумерован. Давайте установим несколько зависимостей между элементами.
- 5+7=3. Это означает, что имея Full backup 5 и Diff backup 7 можно восстановить базу в состояние 3. При этом отсутствие 6 никак не повлияет на возможность восстановления.
- 5+10+11=3. Того же результата (восстановить в состояние 3) можно достичь, если к Full backup 5 применить все изменения, зафиксированные в TLogBackup 10 и 11. Так придется делать, если у нас отсутствуют 6 и 7 из-за того, что расписанием было предусмотрено только создание 5 и 8 (или если 6 и 7 повреждены). Но если 7 есть, то способ 5+7 гораздо быстрее способа 5+10+11.
- Если отсутствует только 7, то базу в состояние 3 можно восстановить способом 5+6+11.
- Если расписание таково, что 11 не создавалось, содержимое 12 будет следующим: «Добавлены: Топорков, Уфимцев, Яшин».
- Журнал транзакций, на первый взгляд, на картинке не представлен, но как вы помните, TLog backup – это никакой не бэкап, а журнал транзакций за определенный период. Обратите внимание, что появление новых фамилий в журнале предшествует их появлению в базе данных.
- Если не создавать резервные копии журналов транзакций, содержимое TLog в момент 12 будет следующим: «Добавлены:», а далее список фамилий 4 (т.е. зафиксированы все действия). Если резервные копии созданы, как на картинке, то содержимое журнала транзакций в момент 4, как и в момент 8, будет следующим: «Никаких действий пока не производилось».
Резервное копирование заключительного фрагмента журнала транзакций
Если речь не идет о системах высокой доступности, то в случае сбоя нужна еще одна уже не регламентная, а ручная операция – создание самого последнего TLog backup. Если это невозможно, т.е. журнал поврежден вместе с базой или вместе с сервером – восстановление возможно только до момента последнего TLog backup, а не на последнюю секунду. Т.е. поставленная изначально цель не будет достигнута.
Из этого следует, что ключевым элементом всей системы резервного копирования является журнал транзакций. Он должен располагаться на отдельном носителе (не совпадающем с носителем для самой базы данных) с очень высокой надежностью, высокой скоростью доступа и высокой доступностью, но ни в коем случае не в разных папках одного логического диска, равно как и на разных логических дисках одного физического носителя. Кроме того, желательно, чтобы даже при падении сервера SQL, журнал оставался бы доступным или хотя бы мог оказаться доступным за минимальное время (методы достижения отказоустойчивости мы не рассматриваем, они составляют тему отдельной статьи внушительного объема).
Именно такая сложная система обеспечит нам достижение поставленных в начале целей и будет свободна от обнаруженных в ходе ее разработки проблем.
Full recovery model (работает только с регламентными заданиями и под контролем администраторов)
Мы описали полную модель восстановления базы данных – Full recovery model. Для особых случаев в MS SQL Server существует простая модель восстановления (Simple recovery model) и модель с неполным протоколированием (Bulk-logged). Full recovery model предусматривает регулярное выполнение задач обслуживания базы данных, а также контроль регулярности и результатов выполнения заданий со стороны администратора. Это предполагает существование сложного инструментария проектирования плана обслуживания (Maintenance Plan), который необходимо изучить.
Перейдем к практике
Возможно, первая трудность, с которой придется столкнуться – невозможно создать новый план обслуживания.
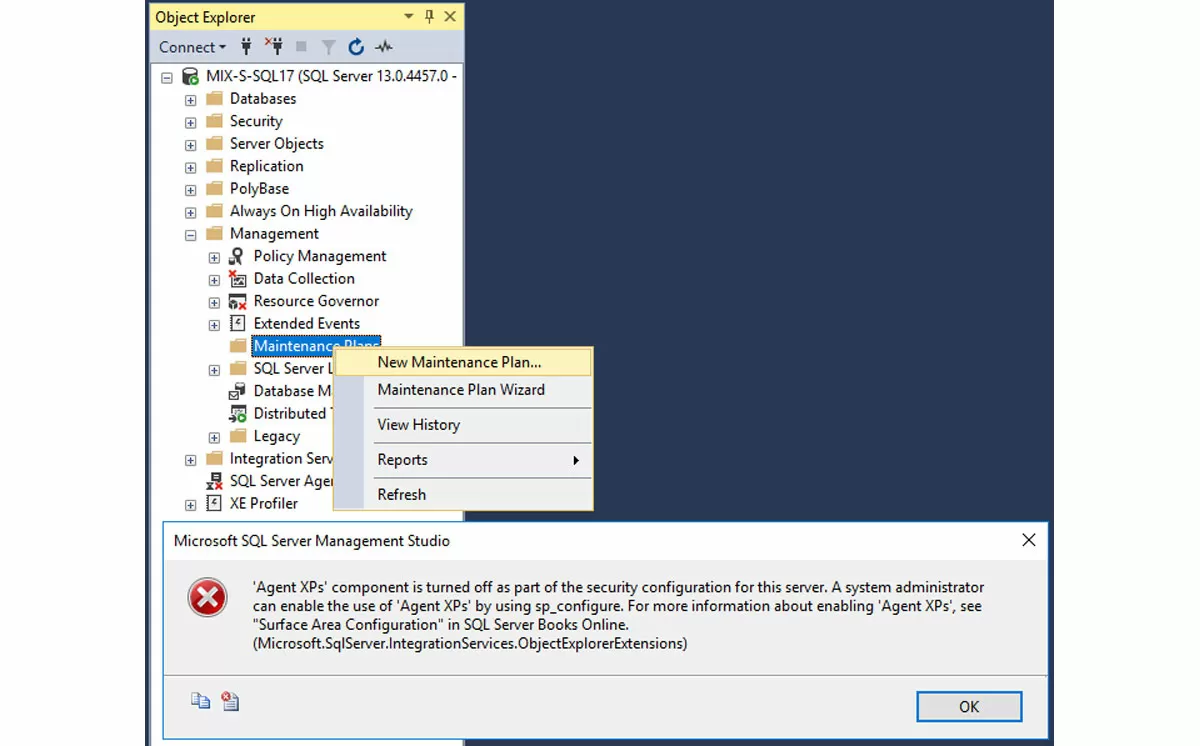
Надо разрешить этот функционал выполнением SQL-скрипта (New Query на панели инструментов, набрать скрипт, Execute на панели инструментов). При успешном выполнении скрипта вы увидите соответствующие сообщения в нижней части окна со скриптом.
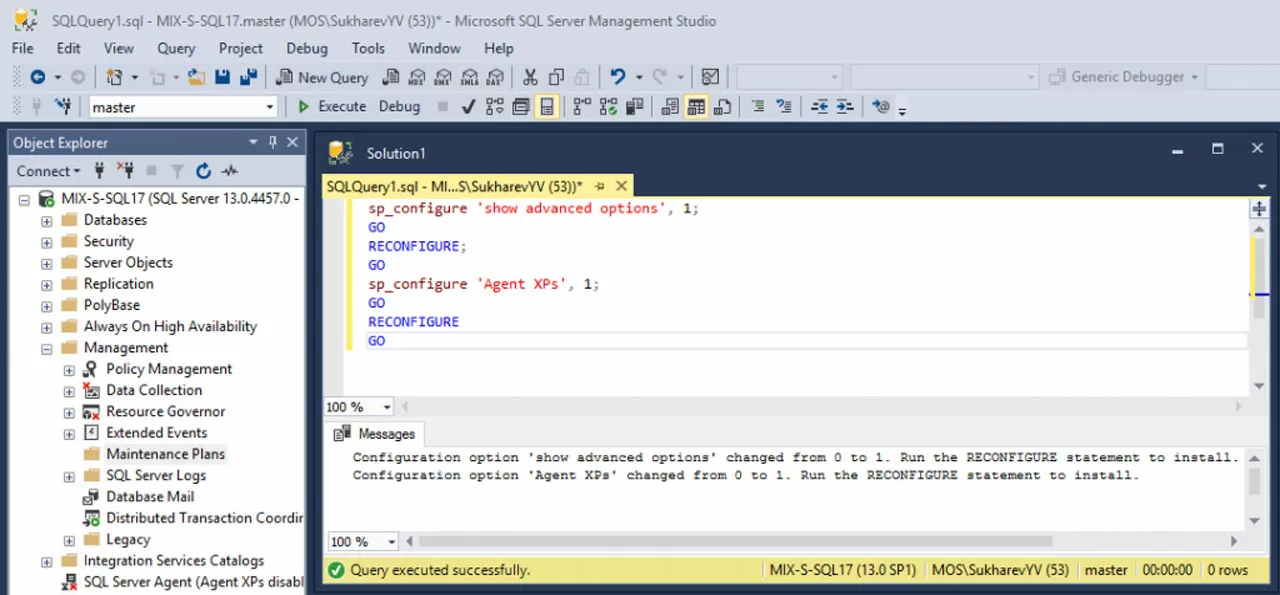
Текст этого скрипта для копирования/вставки:
sp_configure 'show advanced options', 1;
GO
RECONFIGURE;
GO
sp_configure 'Agent XPs', 1;
GO
RECONFIGURE
GO
Реальный план обслуживания
Покажем для начала реальный план обслуживания, обслуживающий непродуктивные базы данных в контуре разработки, а далее рассмотрим отдельные фрагменты плана, необходимые для его чтения и понимания. Четыре иллюстрации ниже показывают план обслуживания «Основной план», состоящий из четырех подпланов, работающих по своему расписанию.
1. Подплан «Ежедневный полный бэкап»
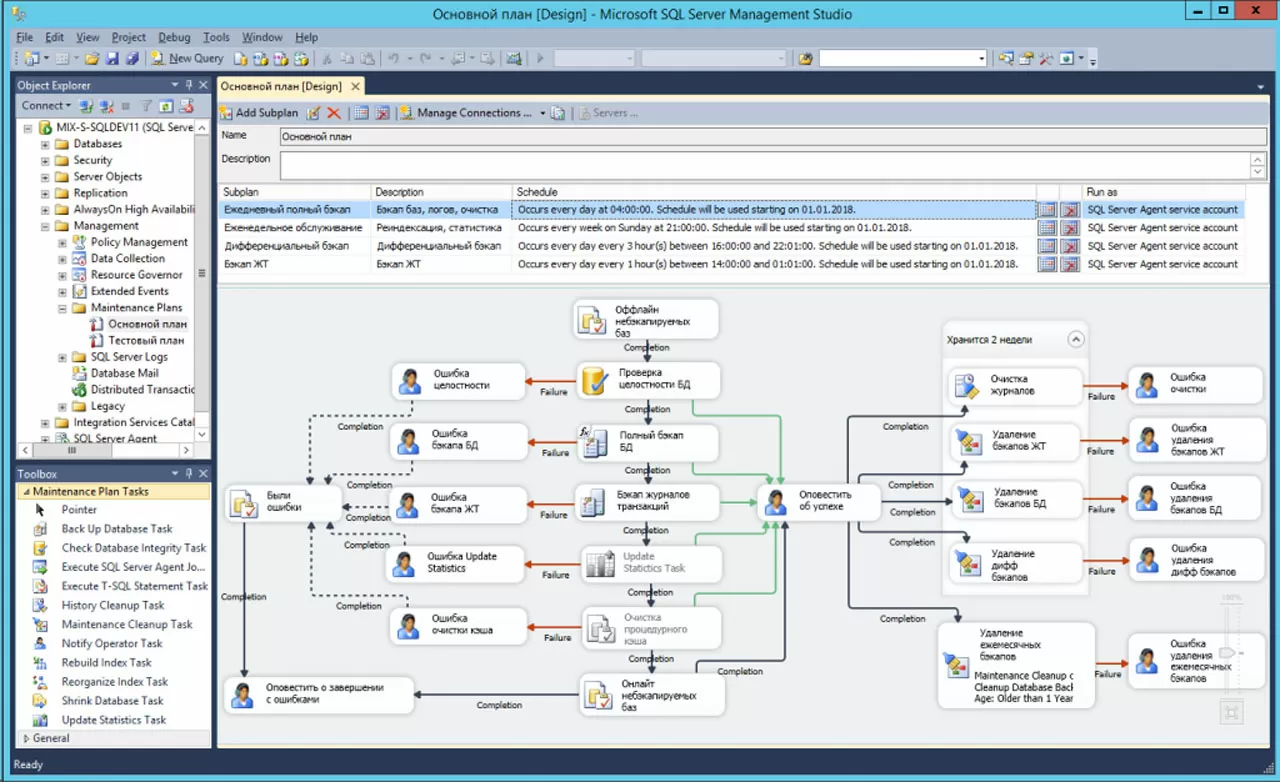
2. Подплан «Еженедельное обслуживание»
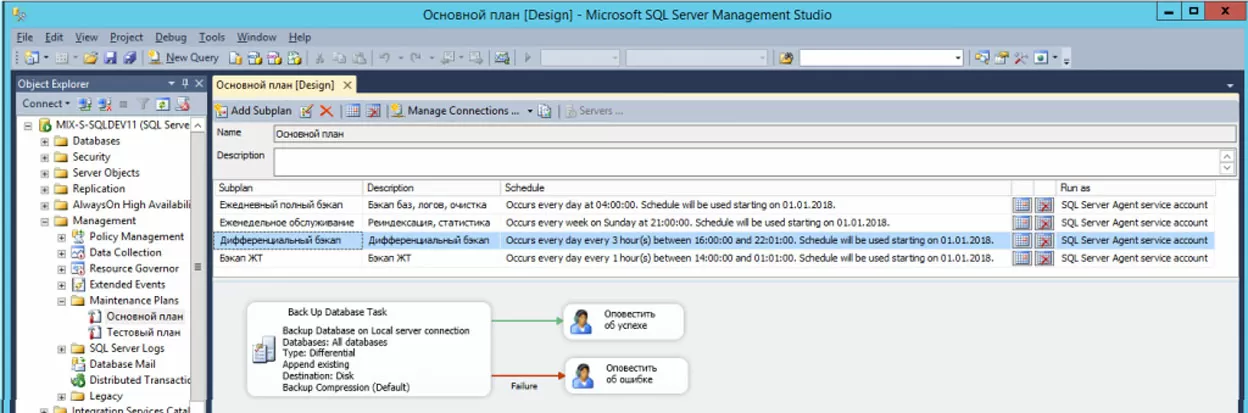
3. Подплан «Дифференциальный бэкап»
4. Подплан «Бэкап ЖТ»
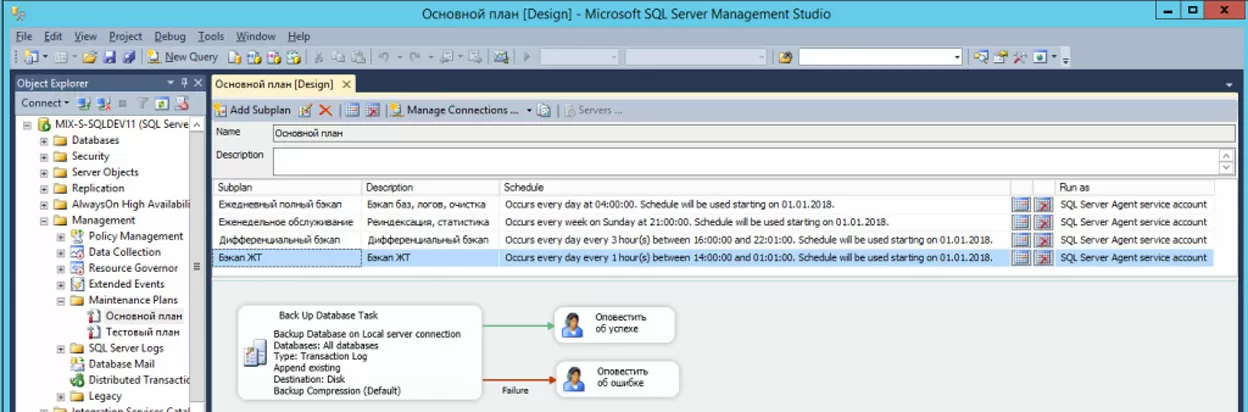
В обозревателе объектов мы видим, что на SQL сервере настроено два плана обслуживания (Основной план, Тестовый план). Основной план состоит из четырех подпланов с разным расписанием (Shedule):
Ежедневный полный бэкап- Еженедельное обслуживание
- Дифференциальный бэкап
- Бэкап ЖТ
В области дизайна задач мы видим задачи. Процесс конструирования плана заключается в перетаскивании задач с палитры Toolbox, установки параметров задач и рисовании стрелок между задачами. Задачи могут иметь произвольное описание в области дизайна, соответствие между задачей на плане и задачей на палитре можно установить по иконкам. Например, задача «Ошибка целостности» – это задача «Notify operator task» на палитре (иконка «человек»).
Это блок-схема?
Первое, что можно подумать, глядя на сценарий выполнения задач плана обслуживания – что это блок-схема, стрелочки обозначают переходы от одной задачи к другой, и по ним можно пройтись указательным пальцем, проследив весь сценарий от начала и до конца. Однако это не так. Бывает, с первого взгляда даже сложно определить, с чего все начинается и какова последовательность выполнения задач. Сценарий в общем случае может начинаться в нескольких местах и заканчиваться также в нескольких местах, потому что SQL сервер стремится запустить абсолютно все задачи одновременно.
Параллелизм и ограничения
Единственное, что его останавливает – наличие ограничений. Задача не может быть запущена, пока не «сбылись» входящие в нее стрелки (ограничения, restrictions). Цвет стрелки обозначает тип завершения влияющей задачи. Входящая зеленая стрелка обозначает для зависимой задачи ограничение «запустить только в случае успешного выполнения влияющей задачи», черная – «запустить только после завершения влияющей задачи (Completion)», красная – «запустить только в случае ошибки во влияющей задаче (Failure)».
Тип линии (сплошная или пунктир) обозначает логический оператор AND или OR для вычисления итогового ограничения от нескольких входящих стрелок. Этот оператор меняется в диалоге Precedence Constraint Editor (двойной клик по любой из стрелок). Сплошные стрелки должны сбыться все, из пунктирных должна сбыться хотя бы одна – тогда зависимая задача сразу будет запущена. Цвет каждой входящей стрелки можно менять независимо (правый клик, Success/Failure/Completion). Тип линии можно изменить только для всех входящих стрелок сразу (двойной клик, диалог Precedence Constraint Editor). Сначала начинают одновременно выполняться все задачи, не имеющие ограничений. Как только завершается очередная задача, проверяются все зависимые от нее задачи и одновременно запускаются на выполнение те, у которых итоговое значение ограничений стало достаточным для принятия решения о запуске.
Информации в предыдущем абзаце достаточно для понимания общего механизма выполнения сервером SQL задач плана обслуживания. Теперь рассмотрим вопросы, имеющие прикладное значение.
Странное расписание
Странное время выполнения задач объясняется разницей 4 часа между часовым поясом серверов и часовым поясом разработчиков. Диапазон возможного времени работы разработчиков с 9:00 до 21:00, поэтому подплан «Бэкап ЖТ» выполняется каждый час с 10:00 до 21:00, фиксируя изменения каждый час (в 9:00 этих изменений еще нет). В переводе на часовой пояс серверов это с 14:00 дня до 01:00 часа ночи, что и указано в расписании.
Переход через полночь

При указании времени можно перескакивать через полночь, это корректно работает. Выглядит немного непривычно. Другие планировщики во избежание трудностей с пониманием времени окончания в следующих сутках запрашивают длительность выполнения задачи – «в течение Х часов».
из мира 1С для ИТ-Директоров
Зачем создавать в одно и то же время полный бэкап и бэкап ЖТ

Если за полным бэкапом немедленно следует бэкап ЖТ – можно быть на 100% уверенным в том, что план создан мастером планов обслуживания (никогда не используйте его, он не создает ничего, кроме мусора) или администратором низкой квалификации, считающим пару Full backup + TLog backup, сделанную в одно время, неким обязательным комплектом для восстановления. А ведь это – независимые задачи, выполняющиеся по разным расписаниям.
Но наш план является исключением, поскольку наша цель – в одном подплане собрать информацию об успешности выполнения ключевых задач (целостность, полный бэкап, бэкап ЖТ), и только в случае их успешного выполнения отдать команду на удаление старых бэкапов.
Если удаление старых бэкапов выполняется безусловно, может оказаться, что новые бэкапы не создаются, а старые окажутся удалены полностью. Если удаление старых бэкапов раскидывается в зависимости от типа бэкапа по разным подпланам – получается почти то же самое. Допустим, перестал срабатывать полный бэкап. При этом перестало выполняться удаление старых полных копий. Но подплан Бэкап ЖТ ничего об этом не знает и продолжает удалять устаревшие бэкапы ЖТ. Через некоторое время у нас не будет не только непрерывной прямой восстановления, но и даже точек восстановления в актуальном окне: последний сделанный полный бэкап сделан слишком давно, а хранящиеся бэкапы ЖТ за последнее время абсолютно бесполезны, т.к. нет ни одного полного бэкапа внутри их непрерывной цепочки.
Задача дифференциального бэкапа ключевой для восстановления не является и в подплане не фигурирует. Но в этот подплан все-таки можно было бы добавить и ее, расположив сразу после полного бэкапа.
Вычисляемые параметры

*Заметьте на задаче значок fx
У каждой задачи есть свойства, часть из которых можно увидеть в диалоге настройки задачи (двойной клик), а полный список – в диалоге свойств (правый клик, Properties). Также в задачах есть свойство Expressions, которое позволяет сформировать таблицу свойств и соответствующих им выражений SQL, для вычисления значений свойств «на лету». Практическая польза от этой возможности следующая. Наверняка вам приходилось видеть т.н. «батники» для того, чтобы удалить все, кроме бэкапов на первые числа, или наоборот, чтобы перед удалением бэкапов скопировать бэкапы на эти числа в какое-то другое место.
Подобные задачи не требуют внешних инструментов и решаются штатными средствами MS SQL. Расширение файла полной резервной копии по первым числам можно сделать MNT, а по остальным дням – BAK. А значит, задача очистки может удалять BAK старше 1 месяца, а MNT хранить более длительное время, удаляя их, например, через 1 год.
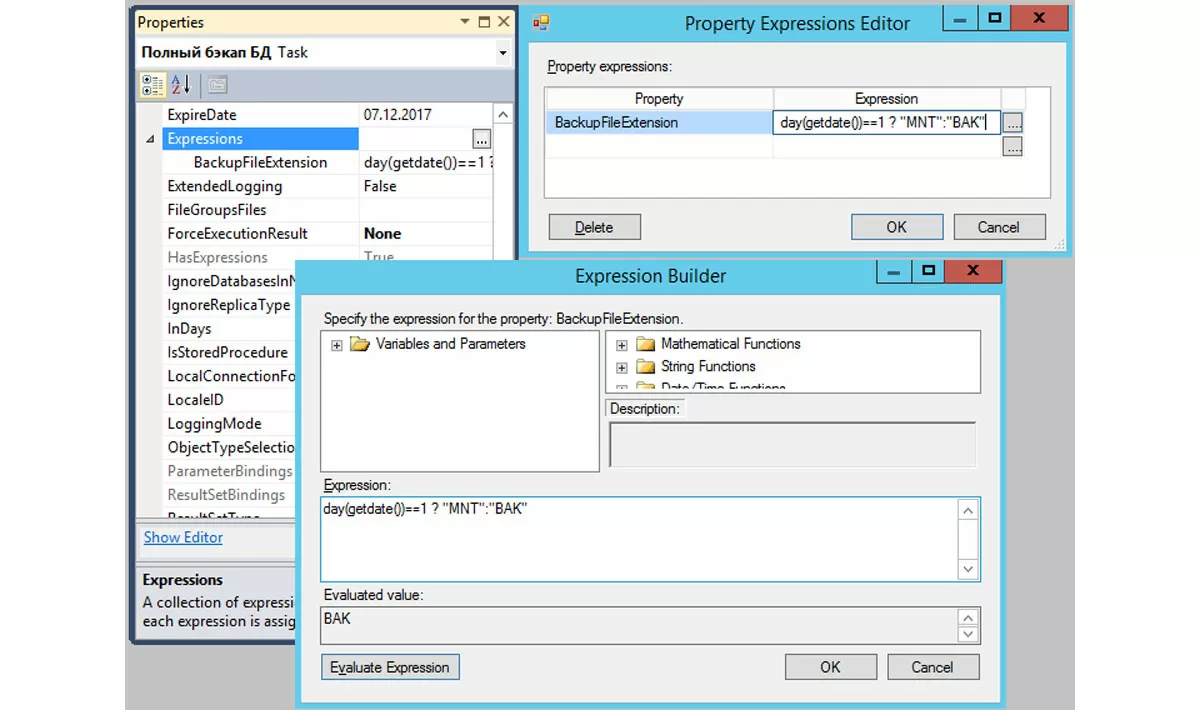
При открытии диалога настройки задачи «Полный бэкап БД» вы увидите расширение файла BAK или MNT в зависимости от сегодняшней даты.
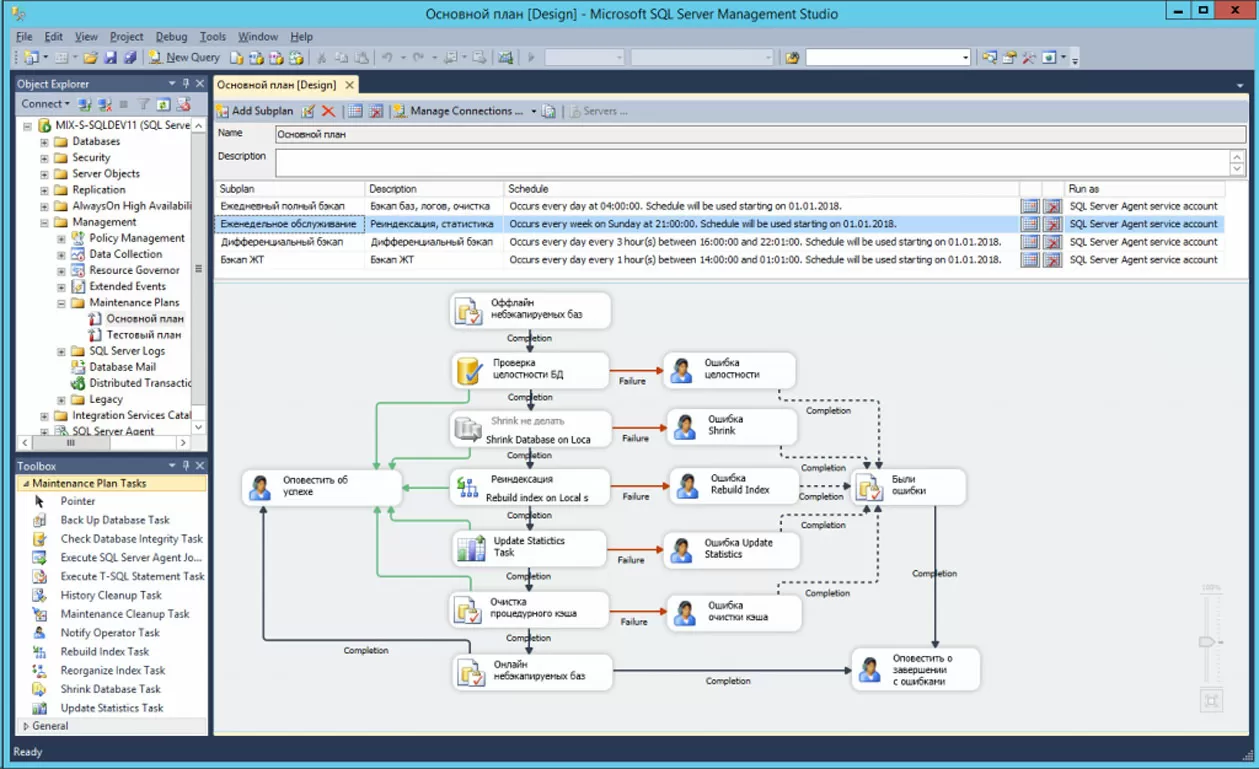
Почему две задачи серые?
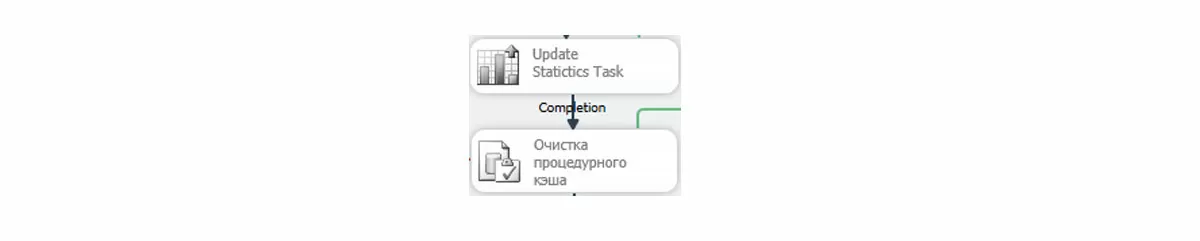
Согласно рекомендациям 1С, обновление статистики должно производиться ежедневно, а очистка процедурного кэша – с частотой обновления статистики. Данные задачи являются достаточно ресурсоемкими с одной стороны, а с другой – не являются принципиальными для информационных баз команды разработки. Ведь такие базы не содержат много данных, и вопросы производительности остро не стоят. Поэтому данные задачи выполняются в еженедельном подплане, а в ежедневном они запрещены (правый клик по задаче, Disable). Не просто отсутствуют, а именно созданы и запрещены.
Рассмотрим закономерный вопрос: а все ли корректно будет работать в запрещенной задаче? Как на такой запрет отреагируют красные, черные и зеленые стрелки?
Запрет задач и моделирование результата
При написании сложных планов обслуживания возникает задача отладки и вытекающие из нее практические потребности:
- Не выполнять долгую задачу фактически, но считать ее условно выполненной, сохранив ее влияние в виде стрелок на остальные задачи;
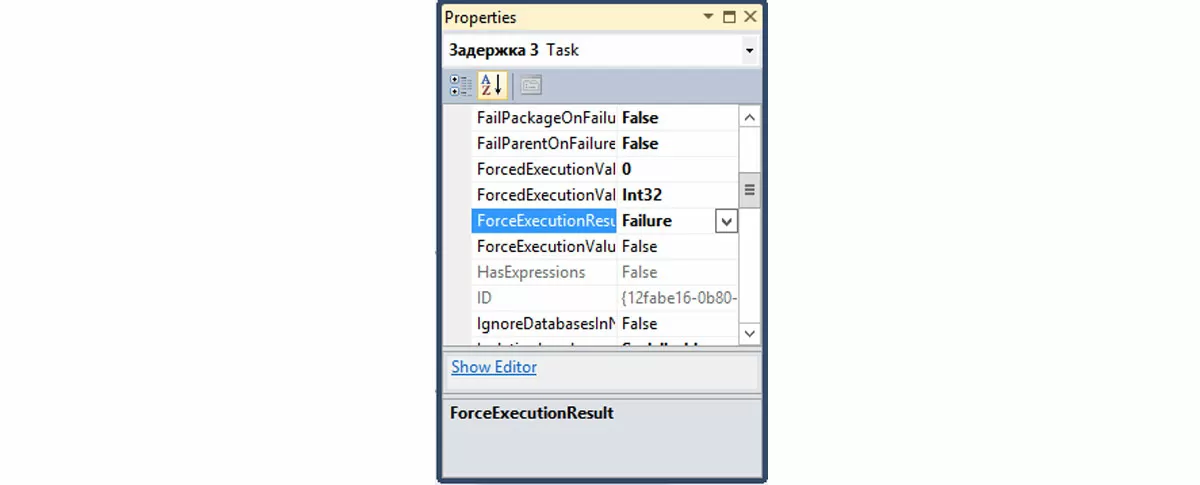
- Моделирование ошибочного выполнения задачи.
Для первого в MS SQL есть механизм запрета фактического выполнения задачи: правый клик по задаче, Disable. При этом задача станет серой, фактически выполняться не будет, но будет считаться как завершенной, так и выполненной (будут работать черные и зеленые стрелки). Если мы хотим смоделировать ошибочное выполнение, то в окне свойств задачи надо установить свойство задачи ForceExecutionResult в значение Failure. Не перепутайте это свойство со свойством ForcedExecutionValue в другом разделе.
Реализация условия ((A or B) and C) для ограничений задачи или фиктивные задачи, которые совсем не фиктивные
Ограничения могут быть объединены или оператором AND, или оператором OR. Это значит, что на иллюстрации ниже пунктирные стрелки Completion нельзя провести непосредственно к задаче «Оповестить о завершении с ошибками». Решение состоит в создании промежуточной задачи «Были ошибки», аккумулирующей результат пунктирных черных стрелок. Задача является SQL-скриптом из одной единственной инструкции go, то есть, казалось бы, ничего полезного не делает.
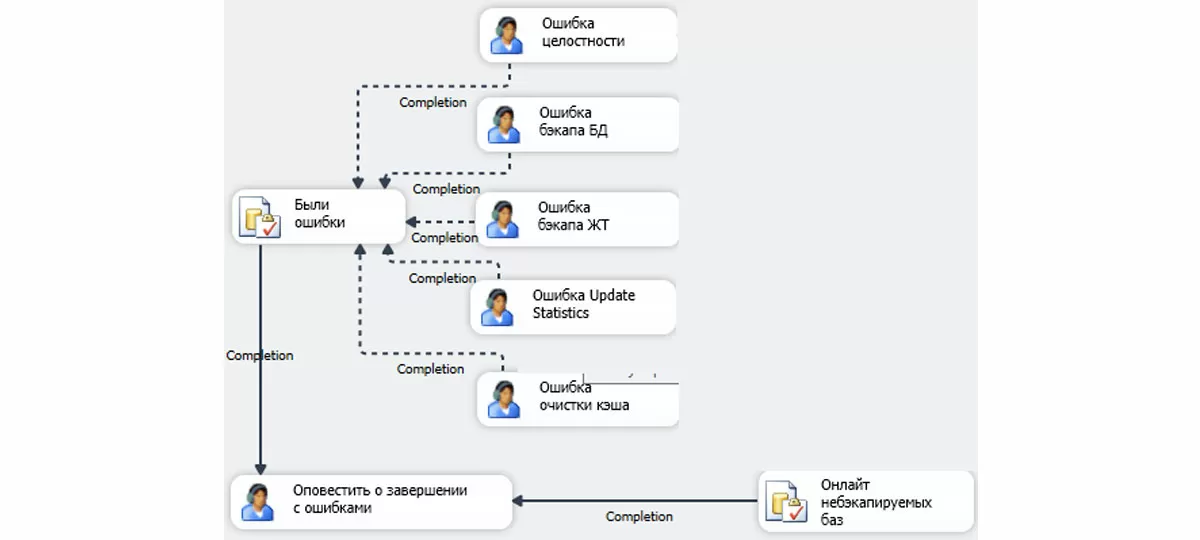
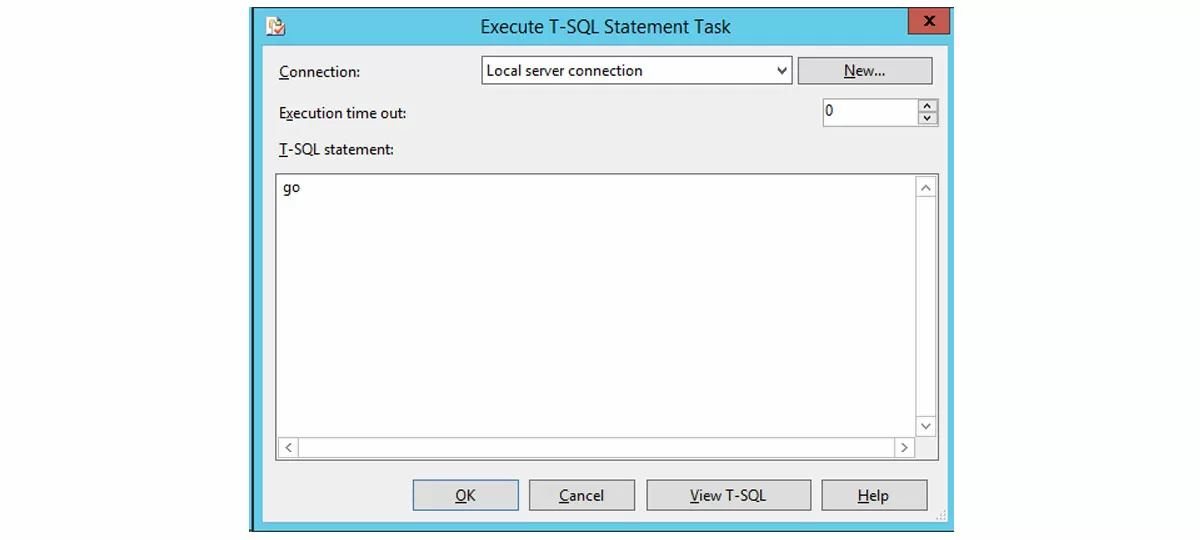
Но на самом деле она собирает входящие ограничения и служит источником ограничений для других задач, являясь, таким образом, важной точкой управления, через которую проходит выполнение сценария. Данный прием с фиктивной задачей можно использовать и в других ситуациях. Например, в вашем сценарии нет нужды переводить базы в состояние оффлайн и затем возвращать состояние обратно. Но просто так задачу «Онлайн небэкапируемых баз» из подплана не удалить, она является важной точкой выполнения, собирая входящие ограничения и служа источником исходящих. В таком случае, надо заменить эту задачу фиктивным сценарием.
Асинхронность выполнения
В конструкции на иллюстрации выше может возникнуть «квантовый парадокс», когда следствие опережает причину. В самом деле, если одна из влияющих задач, например, «Ошибка целостности» дала сигнал к запуску зависимой задачи, ждать результата от остальных влияющих задач уже не имеет смысла, это все равно не повлияет на то, что зависимую задачу «Были ошибки» надо запускать. Поэтому она сразу же выполнится. Еще через некоторое время может случиться так, что сработает и завершится задача «Ошибка бэкапа ЖТ». Она могла бы служить причиной запуска «Были ошибки», но это событие уже произошло ранее. В нашем подплане так и задумано, но такого рода асинхронные эффекты следует иметь в виду, чтобы не получить неожиданные результаты. Например, при замере общего времени выполнения подплана обслуживания с помощью задачи «оповещение оператора» в начале и в конце.
Что это такое?


Это первая и одна из последних выполняемых задач, являющихся скриптами SQL. Дело в том, что в контуре разработки часто присутствуют копии исторических систем весьма большого объема. Они предназначены для ознакомления с ведением исторического учета, служат источником данных в операциях миграции. Данные в них практически не меняются. Оригиналы баз находятся в текущем продуктивном контуре заказчика, копии этих систем всегда могут быть получены по запросу. Бэкапить этот гигантский объем информации – впустую расходовать ресурсы. В параметрах задач, создающих бэкапы, хорошей практикой является указание в задачах бэкапа параметра «All» вместо перечисления конкретных баз данных (это позволяет избежать типичной ошибки «базу создали, а в список бэкапа включить забыли»). А раз так, необходим механизм какого-то исключения некоторых особых баз из множества All. Именно это и делает первый скрип – переводит такие базы в состояние OFFLINE. Второй скрипт выполняет обратную операцию. При этом в параметрах задач бэкапа или реиндексирования ставится параметр «Игнорировать базы в состоянии OFFLINE», иначе возникнет ошибка задания.
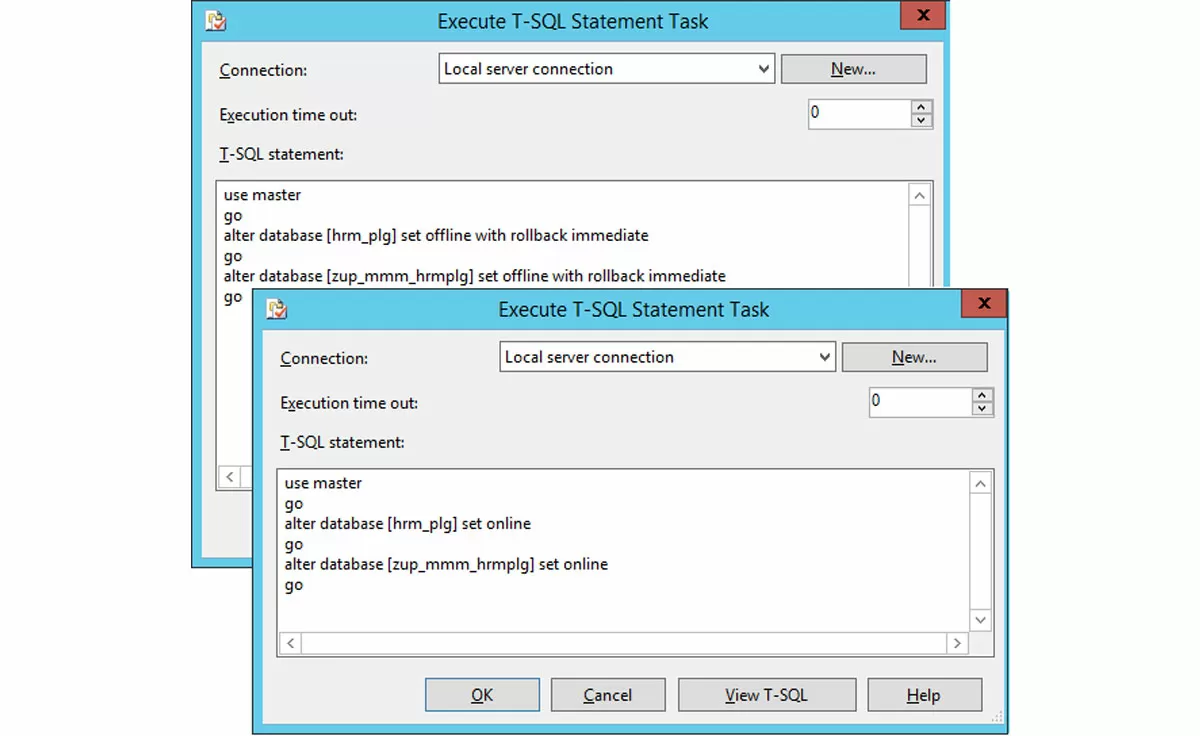
Параллельно или последовательно
В подплане «Ежедневный полный бэкап» самой первой выполняется задача «Оффлайн небэкапируемых баз», т.к. это единственная задача, не имеющая ограничений. Ниже нее мы видим выстроенную последовательность выполнения задач, являющихся основным стержнем подплана «Ежедневный полный бэкап».
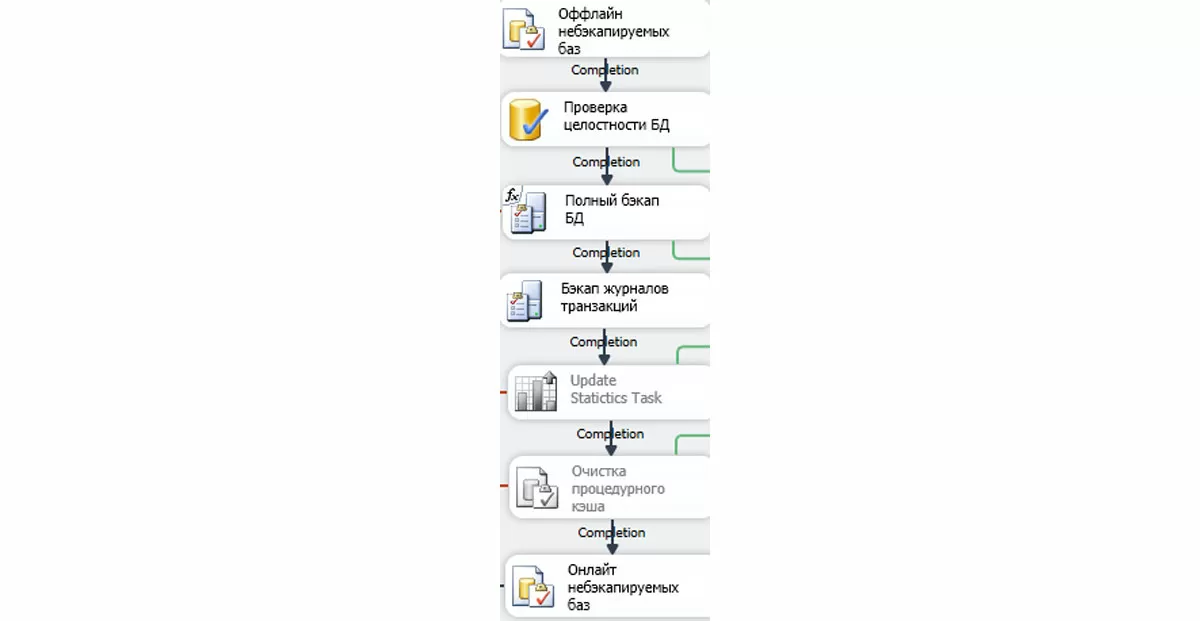
В качестве причин последовательного выполнения назовем, допустим, желание не превысить нагрузку сервера SQL во время обслуживания и наглядность восприятия плана. Обычно, за счет большого ночного окна с перерывом в работе пользователей последовательное выполнение не становится проблемой. Но могут быть ситуации, когда с базой работают много пользователей из разных часовых поясов и окно обслуживания становится очень небольшим. Если последовательное выполнение задач не вписывается в окно обслуживания, их придется распараллеливать. Это можно сделать стрелками, исходящими из «Оффлайн небэкапируемых баз» к каждой основной задаче, а затем сходящимися к «Онлайн небэкапируемых баз». Две серые задачи должны выполняться последовательно по отношению друг к другу. Результат распараллеливания на иллюстрации ниже. Достигаются поставленные цели, но значительно теряется наглядность:
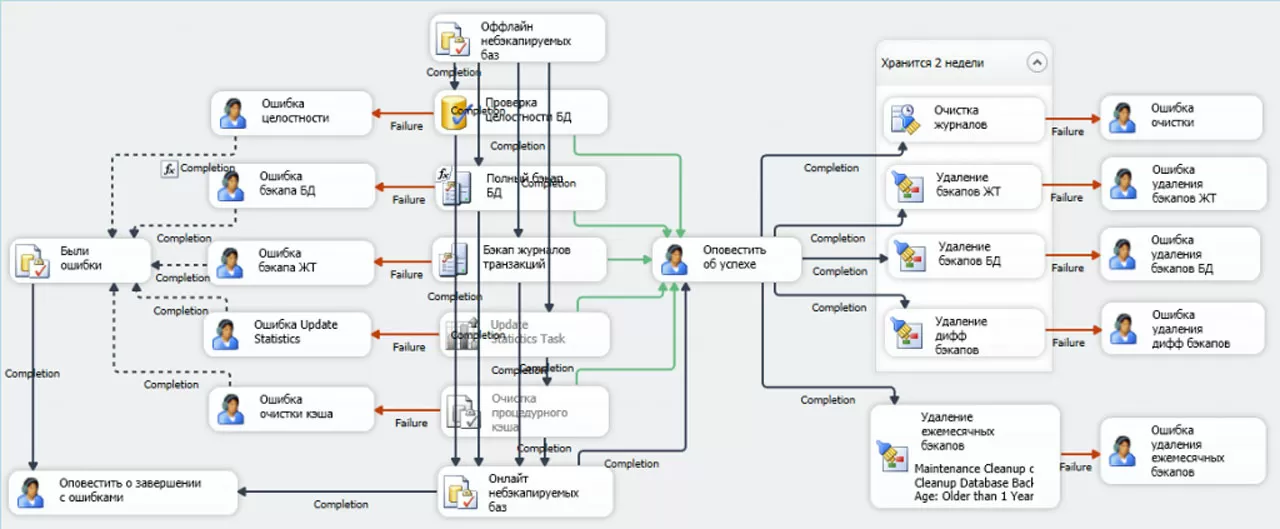
Приведем второй вариант, топологически эквивалентный предыдущей схеме, но более наглядный из-за измененного расположения задач + удаления серых задач.
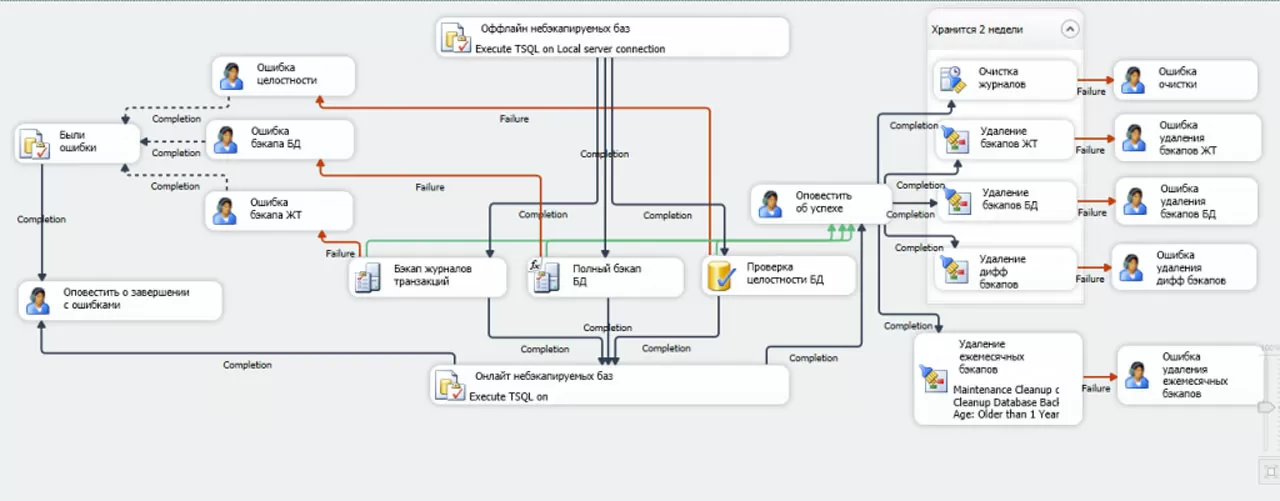
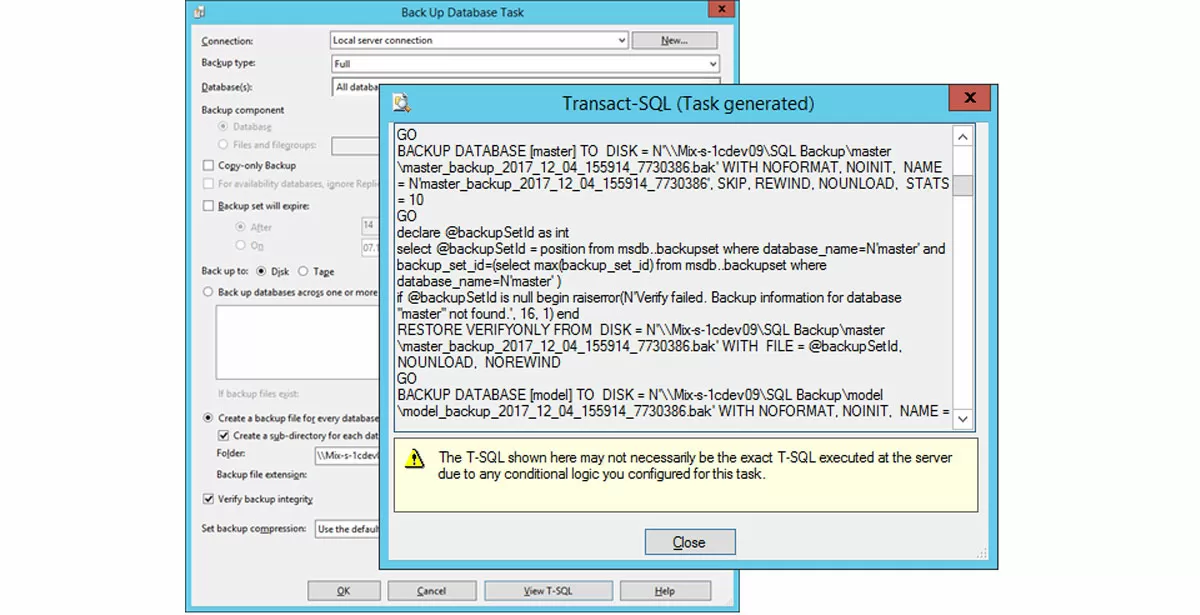
Параллелизм внутри стандартных задач Backup Database и Check Database Integrity и интерпретация результата их выполнения
Задачи «Создание резервной копии» и «Проверка целостности базы данных» работают в общем случае со списком баз данных. Будут ли они работать последовательно с каждой базой данных или возникнет множество параллельных задач обслуживания каждой базы? Выполним двойной клик по задаче, в открывшемся диалоге нажмем кнопку «View T-SQL». Мы видим, что в скрипте, который генерируется и исполняется сервером SQL, инструкции создания резервных копий BACKUP DATABASE разделены инструкциями GO, а значит, эти процессы создания резервных копий будут выполняться параллельно. Результат относится не к пакетам, а к заданию в целом. Если возникла ошибка в задании хотя бы с одной базой – в целом задание будет считаться выполненным ошибочно, если ошибок нет – в целом задание считается выполненным успешно.
Расписание задач обслуживания (ключевой вопрос, часто считающийся второстепенным)
Вспомним главные задачи плана обслуживания базы данных полной модели восстановления:
- Задача Full backup
- Задача Diff backup
- Задача TLog backup
В популярных статьях на тему резервного копирования в среде SQL вопрос расписания задач чаще всего специально не рассматривается или ему отводится второстепенная роль. При этом предлагаемая периодичность выполнения задач внятно не аргументируется. Между тем, данный вопрос является ключевым. Однозначных рекомендаций не существует. Периодичность и состав задач могут быть различными в разных обстоятельствах. Рассмотрим общие принципы.
Главное, из чего надо исходить, это допустимое окно потери данных (Recovery point objective, RPO) + время на восстановление (Recovery time objective, RTO). Эти показатели в свою очередь определяют аппаратную архитектуру, применяемые технологии и периодичность выполнения задач.
Периодичность TLog backup
Периодичность TLog backup зависит от значения RPO. Типовая периодичность задачи TLog backup для продуктивных баз – от ½ до 1 времени RPO на всем суточном интервале времени внесения изменений в базу (включая интервалы времени, на которых происходят изменения регламентными заданиями и разовыми обработками во внерабочее время). Для продуктивных баз характерным является внесение изменений в течение всех 24 часов. Если для такой базы RPO=1 час, то бэкап журналов транзакций должен выполняться круглосуточно каждые 30-60 минут. Но не исключены случаи, когда в силу специфики системы можно ограничиться только интервалом рабочего времени, например с 10 до 18, с понедельника по пятницу, а также большей или меньшей частотой.
Для непродуктивных баз (в среде разработки) более целесообразным может оказаться использование простой модели восстановления, где данная задача вообще отсутствует. Несмотря на то, что в многочисленной литературе и официальной документации декларируется, что использование упрощенной модели не дает выигрыша в производительности (т.к. TLog все равно ведется), на практике это не так. Время выполнения часто выполняющейся операции помещения измененных объектов конфигурации 1С в хранилище при использовании упрощенной модели восстановления сокращается в разы, а суммарный выигрыш по времени резко увеличивает скорость разработки. При этом с периодичностью от ½ до 1 времени RPO надо создавать уже Diff backup. Этот же метод можно использовать для продуктивных бэк-офисных систем с низкой интенсивностью изменения, где есть возможность повторного ввода данных, находившихся в окне RPO и потерянных в результате сбоя.
Взаимосвязанная периодичность Full backup и Diff backup
Периодичность обеих задач в целом подбирается таким образом, чтобы можно было соблюсти RTO. Если интенсивность внесения изменений такова, что позволяет делать полные бэкапы раз в месяц, дифференциальные бэкапы раз в день, и при этом 29-го числа восстановление происходит в рамках RTO – почему бы и нет. Если интенсивность внесения изменений такова, что при такой периодичности задач время восстановления становится неприемлемым – возможно, требуется полная копия на начало дня и несколько дифференциальных бэкапов в течение суток.
Периодичность задачи Diff backup также зависит от объема Diff backup по сравнению с Full backup. Если при выбранной периодичности Diff backup его размер начинает превышать половину размера Full backup, дальнейшее создание Diff backup становится нецелесообразным, в этой точке надо создавать очередной Full backup. Однако стоит помнить, что это соотношение следует игнорировать на относительно новых базах данных – со временем объем ежедневных изменений будет составлять небольшую (т.е. допустимую для Diff backup) часть общего объема данных, а 95% объема будут занимать исторические данные.
Заблуждения экспертов
Следование советам, которые можно прочитать в Интернете на тему настройки резервного копирования в SQL, может стать источником проблем с вашими данными. Давайте применим полученные из этой статьи знания к советам, которые даются некоторыми экспертами:
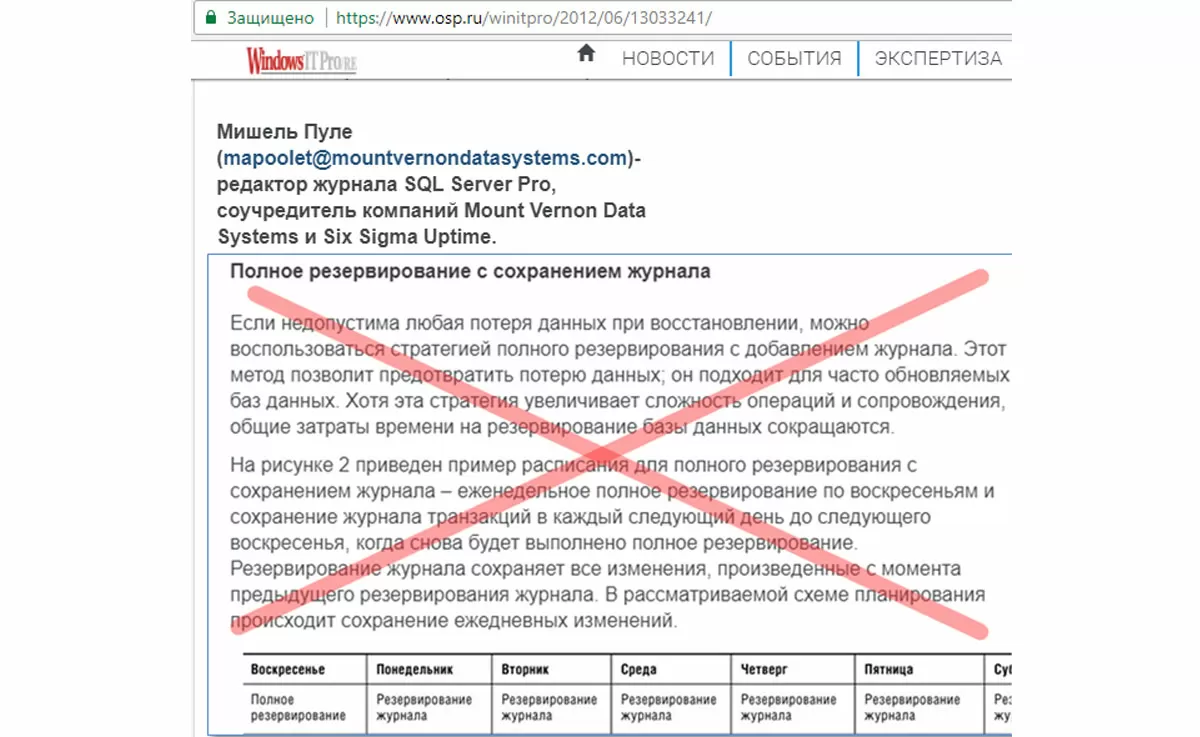
Для часто обновляемых баз предлагается делать Full backup по воскресеньям, а TLog backup 1 раз в сутки. Окно потери данных (RPO)=1 сутки – это недопустимо много. При этом эксперт убежден, что это и есть лучший способ предотвратить любую потерю данных. Недопустимо большим будет также время восстановления в субботу, ведь надо будет применить к Full backup изменения за 6 дней, а интенсивность изменений в базе большая.
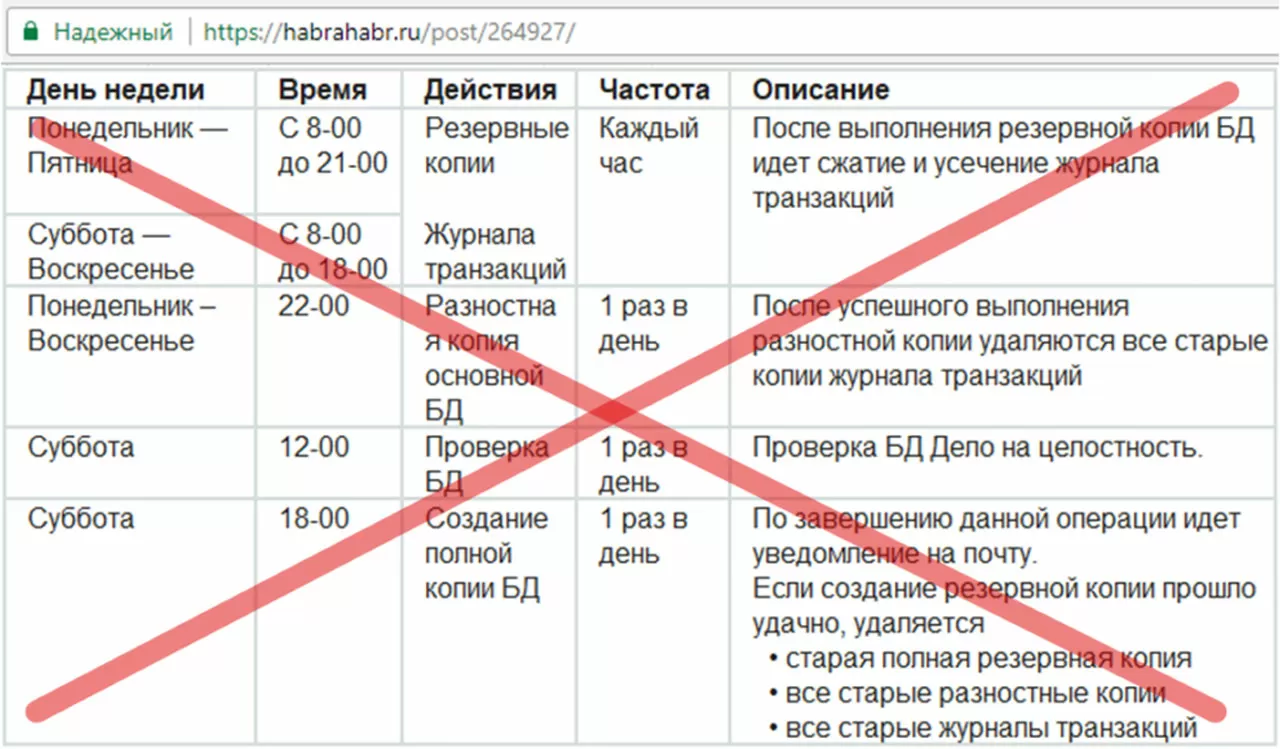
Здесь ежедневно с понедельника по пятницу делается бэкап ЖТ и Shrink ЖТ (Текст «копии БД» в колонке «Описание» – явная опечатка, т.к. в колонке «действия» четко указана операция – бэкап ЖТ). Если вы вернетесь к нашему подплану «Еженедельное обслуживание», то увидите, что задача усечения ЖТ носит красноречивое название «Shrink не делать» и является запрещенной задачей (серая). Поисковый запрос «надо ли делать шринк» поможет уточнить информацию.
Спускаемся на строку ниже и видим, что после каждого Diff backup удаляются TLog backup – это добровольный отказ от непрерывной прямой восстановления (ключевая цель всей системы резервного копирования) и переход к точкам восстановления. Точки отстоят друг от друга на сутки. Это означает, что окно потери данных – сутки (RPO=24 часа).
Спускаемся на последнюю строчку и находим самую крупную ошибку всего плана. Если произошло случайное или злонамеренное повреждение данных, то данные очень надежно хранятся, но являются бесполезными. Представим случай, когда в субботу выходит программист, чтобы разобраться с проблемой «отчеты выдают полную ерунду». В 18:05 он понимает, что наличие проблемы связано с тем, что полностью искажены (удалены) данные ключевых регистров, причем журналы говорят, что это произошло в пятницу после обеда. В этот момент времени у него существует база данных, данные в которой неверны, и один единственный полный бэкап, сделанный 5 минут назад, данные в котором также неверны. Все остальное начисто удалено, т.к. был успешно создан полный бэкап. Этот план обслуживания – чемпион по количеству сделанных ошибок.
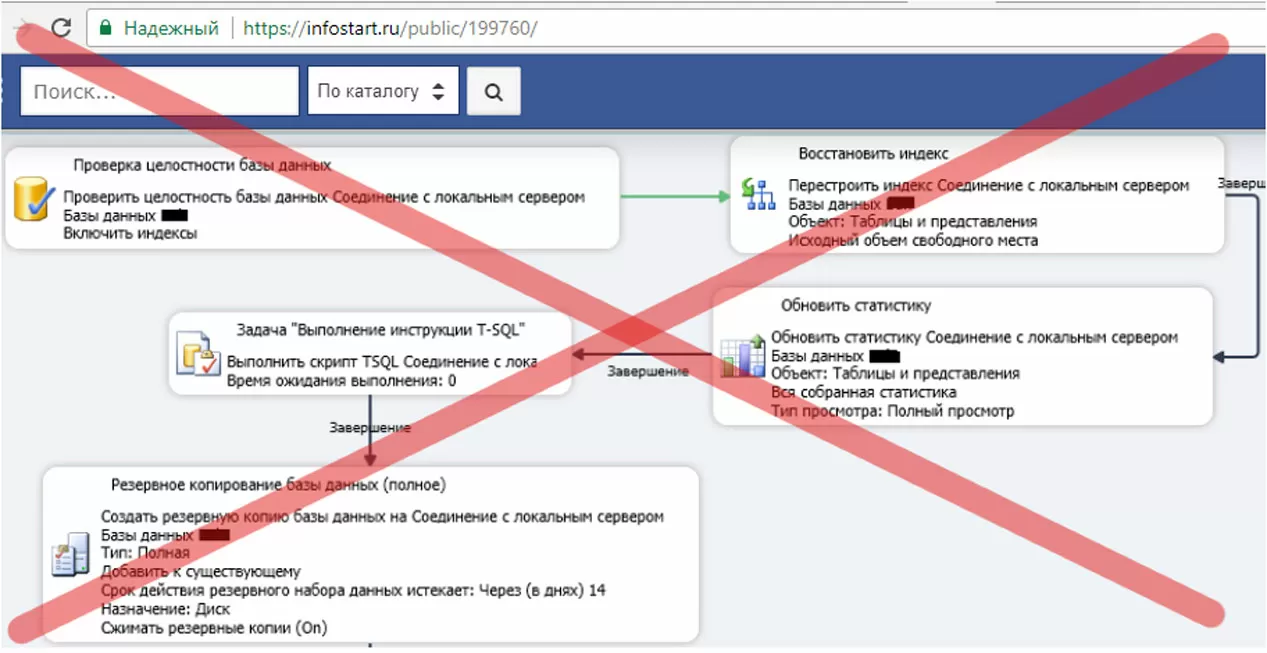
На иллюстрации выше – план начального уровня, созданный начинающим специалистом с помощью мастера Maintenance Plan Wizard и не решающий никаких задач. В нем имеется распространенная ошибка: нельзя ставить задачу создания полной резервной копии в зависимость от результатов проверки целостности. При падении базы данных лучше иметь резервную копию с двумя «битыми» ссылками в базе, чем не иметь ничего. Сравните с тем, как сделано в подплане «Ежедневный бэкап» – нарушение целостности информирует оператора, но не препятствует созданию бэкапов.
Особенности восстановления – как не потерять данные
Казалось бы, что может быть проще: просто откатить базу данных на некоторое время назад из ее собственного бэкапа. И немногим сложнее развернуть в базе бэкап другой базы. Но на этой простой операции нас подстерегают большие опасности, в результате которых можно запросто потерять свои данные. Кроме того, надо честно сказать: в диалоге восстановления столько несуразного, что начинающему специалисту обязательно будет казаться, что он что-то не понимает и делает что-то не так, даже если он все делает правильно.
Поскольку эти «особенности» нигде не описаны, давайте восполним этот пробел. Рассмотрим типовую задачу восстановления продуктивной базы по состоянию на какое-то время (источник, ZUP3ENERGO на иллюстрациях) в индивидуальную базу программиста (приемник, ZUP_SUV на иллюстрациях) для расследования инцидента. Описывая различные «особенности» поведения разных версий SQL сервер, под термином «новые версии» мы будем подразумевать релиз 13.0.4457.0, а под термином «старые версии» – релиз 11.0.3156.0.
Первое действие – правой кнопкой по базе-приемнику, Tasks, Restore, DataBase. И сразу же в диалоге Restore Database (иллюстрация ниже) мы видим желтый знак опасности: будет сделана резервная копия заключительного фрагмента журнала транзакций базы-источника. Конечно, на самом деле речь должна идти о базе-приемнике и логика тут должна была бы быть следующая: прежде чем уничтожить текущее содержимое восстановлением, давайте на всякий случай окончательно зафиксируем то, что есть сейчас. Это позволит откатить текущее восстановление назад, выполнив впоследствии еще одно восстановление на точку перед восстановлением. Операция, казалось бы, полезная и ничего опасного в ней нет, если бы речь действительно шла о приемнике. Но это не просто ошибка в сообщении, tail-log backup ошибочно выполняется для источника. Это можно проверить экспериментально, нажав кнопку Script и посмотрев код.
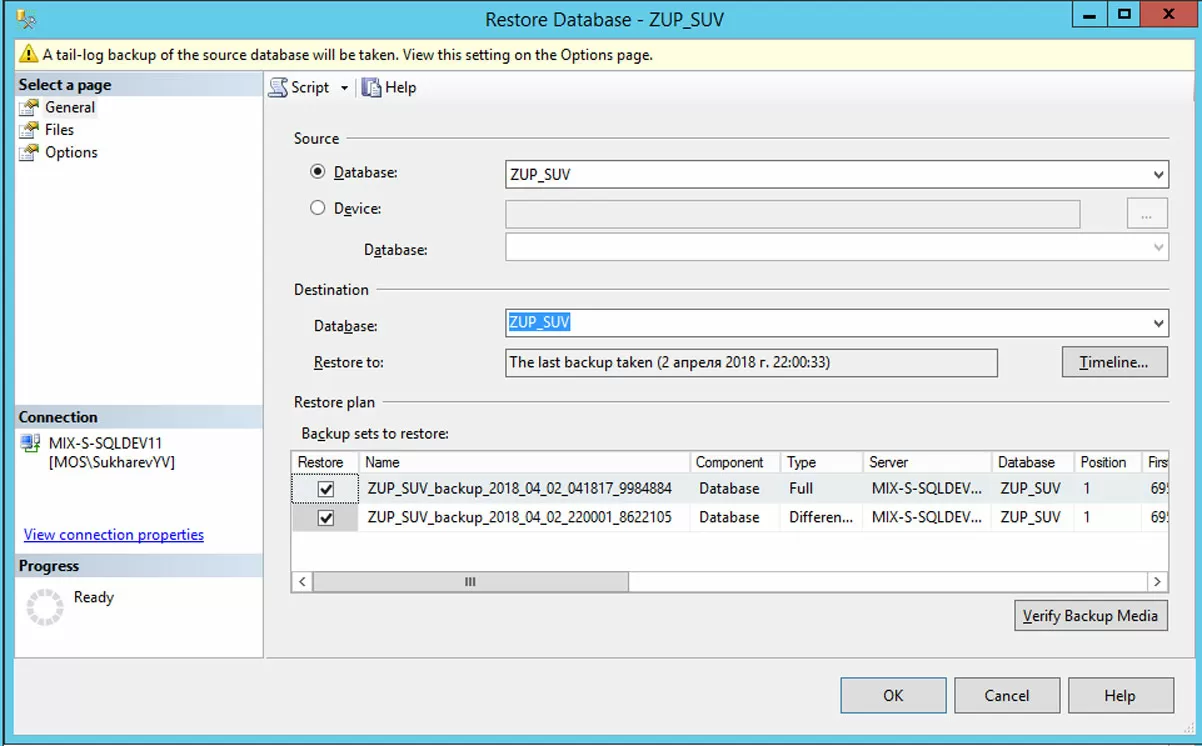
Поэтому на пятом шаге надо отменить эту операцию (см. далее). Фиксирование самых последних изменений с приемником (которые могли произойти за время, прошедшее с момента создания последнего бэкапа ЖТ) необходимо делать вручную (например, внеплановым запуском соответствующего задания).
Дадим также общую рекомендацию: обязательно читайте все сообщения в верхней части диалога – любое незнакомое длинное сообщение должно вас насторожить!
Теперь давайте разберемся, что на самом деле может служить источником. В диалоге видно, что источником может быть Database и Device. Надо ли объяснять, что непосредственно база данных не может служить источником данных на произвольный момент времени в прошлом. Источником могут быть бэкапы базы данных. Поэтому требуется пояснение опций.
- Источник Database – все множество файлов, содержащее в себе бэкапы базы-источника и ее журналов согласно реестру бэкапов, который ведется в системных таблицах SQL сервера. «Согласно реестру бэкапов» – крайне важная фраза для понимания механизма операции. Она означает, что даже если в настоящее время какой-то файл отсутствует на диске, он может оказаться учтен в плане восстановления (т.к. зафиксирован в реестре) и появится в списке Backup sets to restore. Ошибка возникнет только на стадии восстановления и если это файл Diff backup или TLog backup – база останется в состоянии, непригодном к использованию. Чтобы этого не произошло, предварительно проверяйте возможность восстановления кнопкой «Verify backup Media».
- Источник Device – произвольный набор файлов. Дело в том, что история бэкапов может быть очищена. Или бэкапы создавались на другом сервере SQL и поэтому не зарегистрированы в реестре бэкапов на этом сервере. Поэтому имеется возможность явного указания произвольного набора файлов. Указать можно избыточный для восстановления набор файлов (например, за много дней – SQL сервер на следующем шаге подберет только необходимые).
Второе действие – выбираем источник, который в нашем случае отличается от приемника. Новые версии MS SQL Server реагируют на это нормально. В более старых версиях происходят неприятные эффекты, которые необходимо тщательно отслеживать во избежание потери данных:
- Эффект 1. MS SQL сразу же меняет Destination на базу данных, указанную в Source. Поэтому Destination надо вернуть назад. Если вы не заметите этого – база будет молча перезаписана, и даже снятый флаг «Overwrite the existing database» на закладке Options не сможет ее защитить;
- Эффект 2. Переключаемся на закладку Files и видим – вместо приемника MS SQL Server хочет перезаписать источник (см. следующую иллюстрацию). Необходимо руками вбить имена файлов базы-приемника и ее журнала, иначе будет потерян источник (см. далее четвертое действие).
Третье действие. После выбора набора файлов в качестве источника необходимо уточнить момент времени (Restore to, кнопка Timeline). Уточнение момента времени позволяет из исходного множества файлов, определяемых источником (Source), выбрать конкретный набор (Backup sets to restore), необходимый для восстановления на указанное время. Становится очевидной еще одна несуразность, присутствующая даже в самых последних версиях MS SQL: опция «Restore to» и кнопка TimeLine нарисованы в диалоге совсем не там. Они, безусловно, относятся к источнику, а не к приемнику. Эта ошибка не будет исправлена никогда, ей более 10 лет, поэтому к ней надо просто привыкнуть. Будьте также очень внимательны при ручном вводе времени без использования линейки: даже последние версии SQL сервера «съедают» первый ввод числа месяца, так что число необходимо будет ввести два раза.
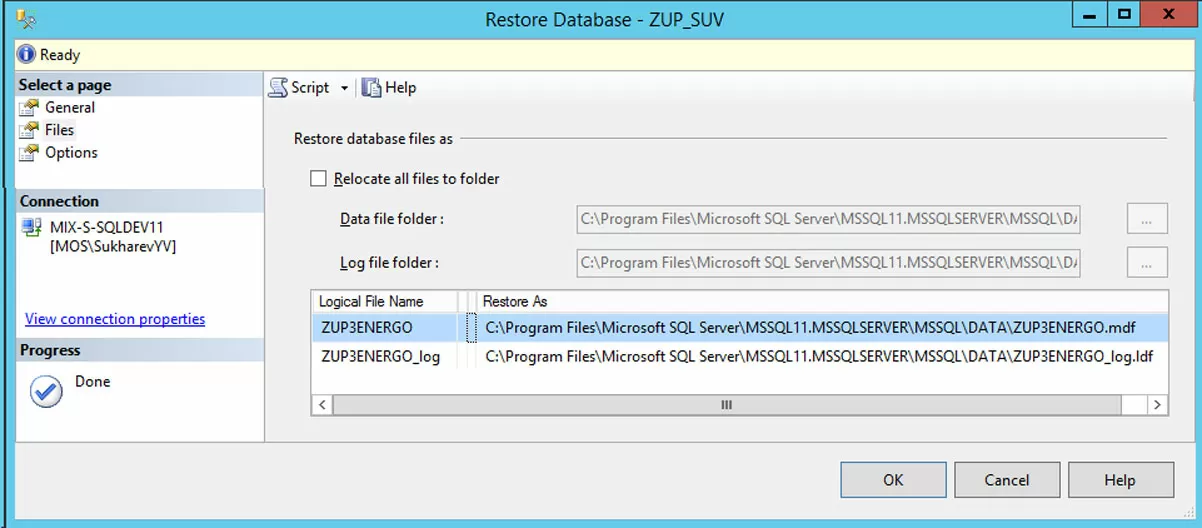
Четвертое действие. Переключаемся на закладку Files и вручную вбиваем имена файлов базы-приемника и ее журнала.
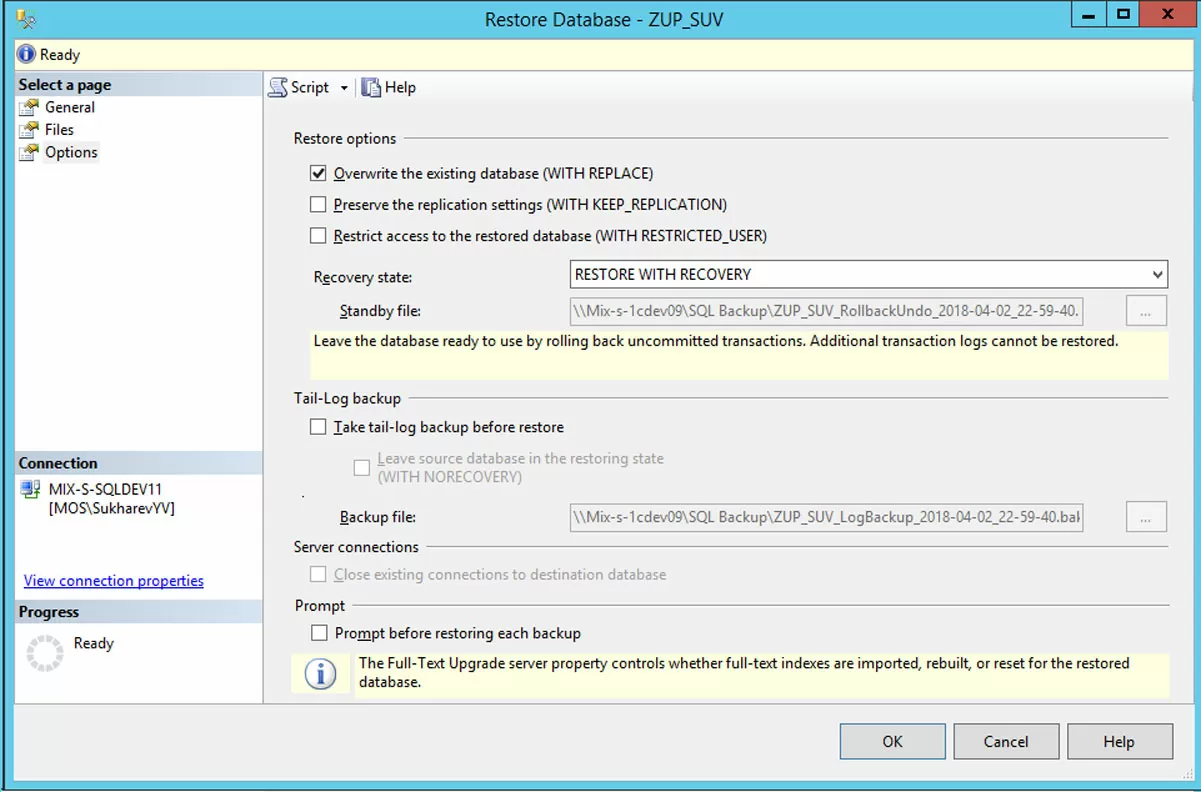
Пятое действие. Переключаемся на закладку Options. Поставьте опцию перезаписи базы данных, снимите опцию создания заключительного фрагмента ЖТ, включите опцию «закрыть существующие подключения к базе-приемнику», если она доступна:
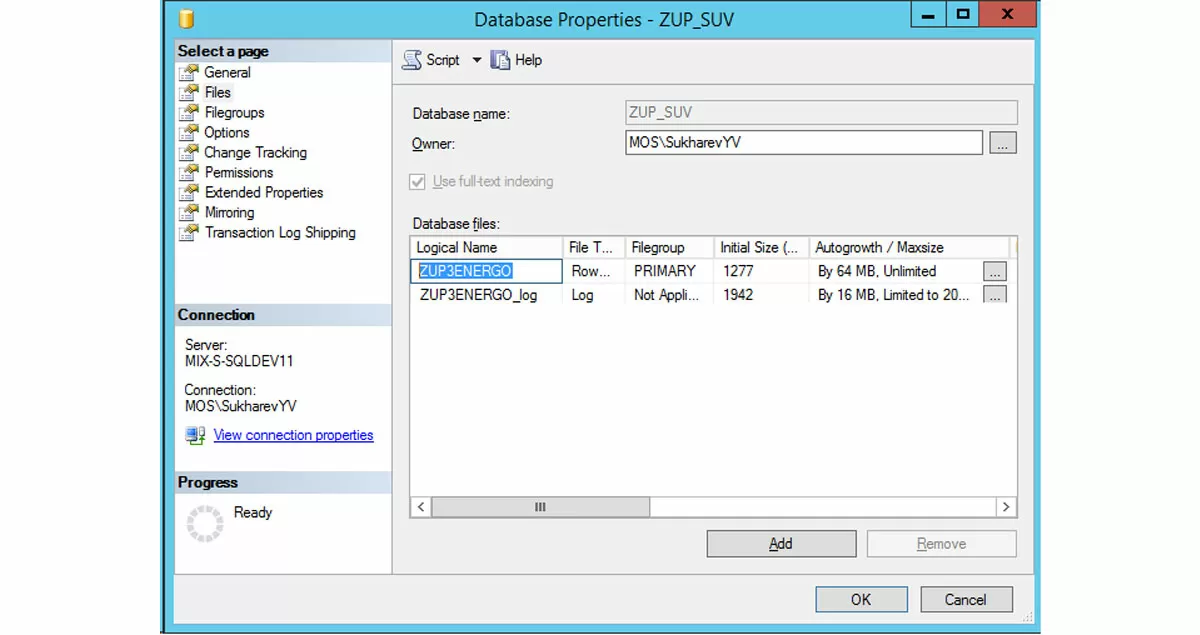
Шестое действие. После восстановления из «чужого источника» восстановленная база (ZUP_SUV) получит чужое логическое имя (ZUP3ENERGO). Его необходимо вернуть назад в диалоге свойств базы данных (правый клик по базе, Properties). Если этого не сделать, то наступят очень неприятные последствия.
Удачи вам и вашим данным!
консультация эксперта

самые свежие новости 1 раз в месяц


