Руководитель управления информационных технологий компании WiseAdvice Олег Филиппов в рамках INFOSTART EVENT 2017 COMMUNITY рассказал о возможностях использования в среде 1С OpenSource-решения – столбцовой базы данных ClickHouse. Наряду с такими СУБД, как HP Vertica, а таже Cassandra и Hive, разработанных в рамках Facebook, и BigQuery от Google, ClickHouse – разработка Яндекс, показывает отличные результаты работы. По мотивам этого выступления мы подготовили статью.
Для разработки в среде 1С характерны две крайности: разработчик «прикручивает» всевозможные инструменты, чтобы выполнить задачу, для реализации которой в 1С и так все есть; и наоборот – разработчик, не прибегая к внешним «помощникам», пытается реализовать целиком на 1С поисковый движок или 3D-игру, например.
И тот, и другой путь правильным назвать сложно. Даже имея в виду, что 1С располагает достаточно мощной платформой для разработки бизнес-приложений, не стоит искать «лекарство» на все случаи жизни. Важно оценить весь имеющийся арсенал возможностей, в том числе и из числа внешних технологий, и выбрать под конкретную задачу наиболее эффективные специализированные инструменты.
В качестве такого инструмента мы рассмотрим бесплатное OpenSource-решение от компании Яндекс – столбцовую базу данных ClickHouse, предназначенного для работы с по-настоящему большими таблицами/системами, а также ситуации, когда он покажет максимальную эффективность, и наоборот – когда его применение будет излишним.
Видео выступления


Что значит «большая таблица»?
Что можно назвать по-настоящему большой таблицей, для работы с которой стоит использовать такой инструмент, как ClickHouse? 1 048 576 строк – это большая таблица? Но что же тогда говорить о таблице со ста миллионами записей?
Большая таблица или нет – определяется сугубо потребностями пользователя. Что это значит? Универсальный способ определения больших таблиц – это APDEX, вне зависимости от того, идет ли речь о BigData или нет. Реальный объем записей значения не имеет.
Приведем пример: если в таблице миллион записей и столько же запросов в секунду, но при этом скорость обработки данных не устраивает конечных пользователей (излюбленная пользовательская жалоба – «все висит»), эту таблицу смело можно назвать большой и применять к ней принципы работы OLAP и BigData. Наряду с этим, таблица со ста миллионами записей, обращение к которой происходит, условно, единожды в год, может смело считаться маленькой.
Но даже при работе с большими таблицами, у которых не выполняется APDEX и из-за «тормозов» которых регулярно поступают жалобы пользователей, ClickHouse нужен далеко не всегда. Рассмотрим ситуации, когда можно обойтись без него.
Сжатие таблиц СУБД*
*эти действия нарушают лицензионное соглашение с 1С.
Это первое действие, которое приходит на ум, в борьбе со сложившейся ситуацией. Сегодня сжатие решает не только проблемы отсутствия места на диске (более того, большинство СУБД, не исключение и ClickHouse, сжимают данные по умолчанию).
В большинстве высоконагруженных систем дисковая подсистема является «бутылкой»: запись на диск, даже твердотельный, происходит не так быстро, как работает память и процессор. В итоге процессор загружен на 15%, а большая таблица «тупит», чем вызывает бесконечный поток жалоб от пользователей. Сжатием таблицы мы радикально ускорим операцию записи, пожертвовав при этом ресурсами процессора – процессорным временем, но как раз этого мы и добиваемся, потому что его «не жалко»: процессор стоит недорого, его можно виртуализировать, количество его ядер можно увеличивать и перераспределять. При этом наращивание объемов дисковой подсистемы на скорость работы никак не повлияет.
Пример кода сжатия таблицы SQL-сервера*
ALTER TABLE Table
REBUILD PARTITION = ALL WITH
(DATA_COMPRESSION = ROW/PAGE);
Тут стоит обратить внимание на то, что ROW – это не совсем то сжатие, которое нам нужно. А вот выполнение PAGE может повысить производительность в пять-десять раз, плюс – сэкономить место.
*Для этого требуется лицензия SQL-Server уровня Enterprise (если говорить про Microsoft SQL Server).
Секционирование таблиц
Следующий шаг, если сжатие не дало целевых результатов, – разбить таблицу на секции и распределить их по дисковым подсистемам: нужно определиться с «отправной» функцией, в соответствии со значениями которой данные будут разделены, а после ее применения «разделенные» секции таблицы разложить по разным файловым группам и даже на разные диски. Это позволит работать не с огромной таблицей целиком, а с ее маленькой частью.
Кубы, InMemory
Если и это не помогло, можно прибегнуть, несмотря на их небольшую популярность, к кубам или InMemory*, которые, кстати, могут быть и среди OpenSource-решений.
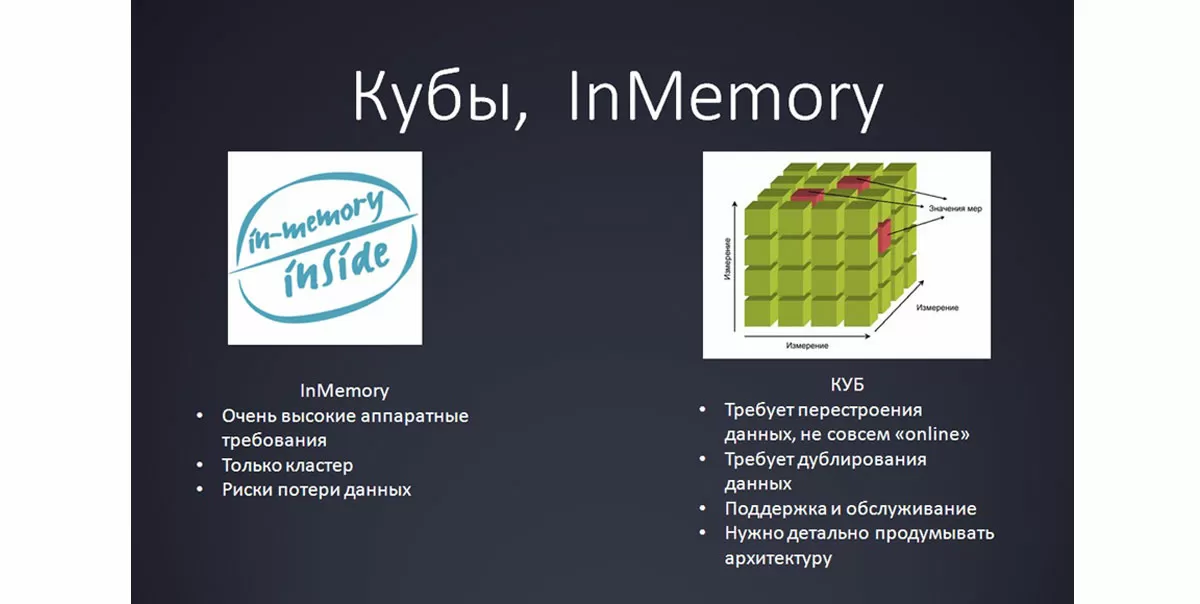
*Особенно стоит рассмотреть эти технологии, если вы уже используете MS SQL Analysis Services, BI-решения, или у вас есть компетенции по OLAP.
Пришло время ClickHouse
Когда все средства в борьбе за производительность испробованы, но ничего не помогло, и, казалось бы, пришло время ClickHouse, все-таки стоит задаться вопросом: «Нужна ли по данным, с которыми мы хотим работать, агрегированная информация?».
Приведем еще один пример, когда ClickHouse все еще «overqualified». Вы хотите хранить историю и получать логи журнала регистрации. Как правило, он объемный, и поиск по имеющемуся объему данных вызывает трудности. Но такие задачи можно решить с помощью, например, ElasticSearch. Эта СУБД как раз подходит (что многие в сфере 1С уже давно признали и успешно используют) для хранения и простого поиска определенной записи.
ClickHouse стоит использовать, когда необходима агрегация данных, то есть сбор огромной массы информации о каких-либо частых, но мелких событиях, которые происходят регулярно, возможно, прямо сейчас, с последующим анализом этой информации статистическими методами.
За счет чего ClickHouse – представитель столбцовых/колоночных СУБД, имеет скорость обработки гораздо более высокую, чем у стандартных реляционных? Когда чтение*-запись-хранение-обработка осуществляется не по строкам, а по колонкам данные, во-первых, проще сжать, во-вторых, нам не нужна нормализация, которая, как раз, и нацелена на разделение колонок, чтобы «разбить» строки-пласты, а в-третьих, при выборке с диска в память считывается сразу значительный объем данных, что ускоряет запросы в десятки раз.
*Особенно чтение, поскольку это OLAP-решение.
В качестве примера рассмотрим взятое с сайта разработчика сравнение скорости работы ClickHouse и самой популярной (и дорогой) СУБД – HP Vertica.
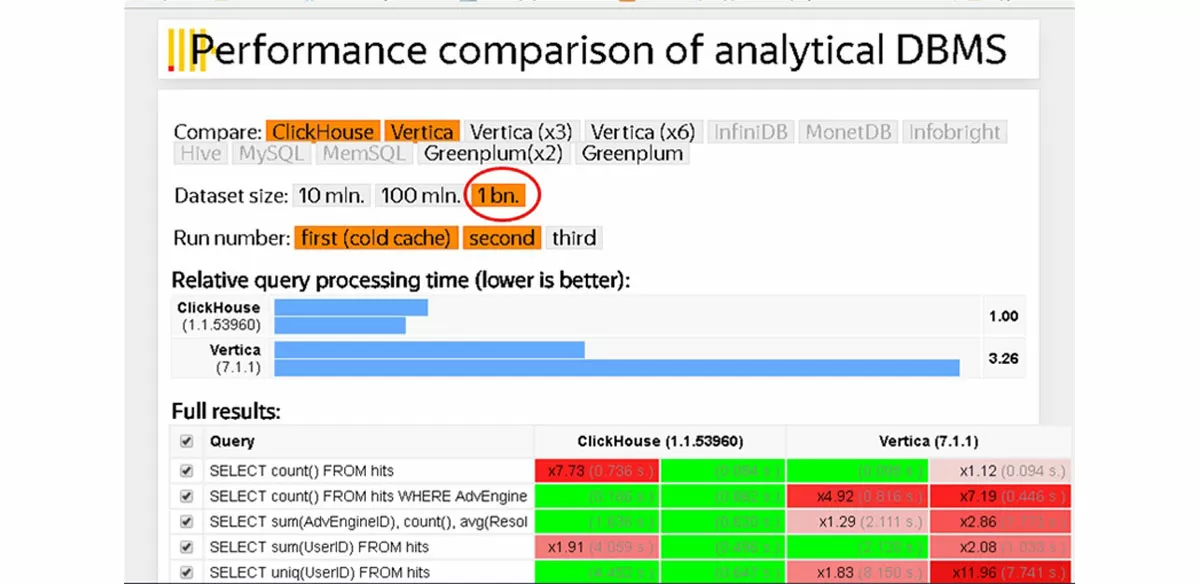
Официальная статистика по ClickHouse говорит о том, что запросы к таблице в один миллиард записей на SQL-сервере, выполняются не за часы и даже не за минуты. Count(*) по таблице из одного миллиарда записей – 0.1 секунда, 0.06 секунд.
Ограничения
Конечно, у ClickHouse есть ограничения, которые делают его специализированным решением, а не «СУБД на все случаи жизни». Например, в ClickHouse отсутствуют операции Delete и Update, поскольку данный инструмент разрабатывался под нужды Яндекс.Метрики, а там не было такой потребности (пользователь кликнул, статистика по операциям сохранилась в базе, удалять или менять ее не нужно). Также с драйвером ODBC еще достаточно много проблем, и к 1С как к внешнему источнику его пока не подключишь. Помимо этого, для ClickHouse характерна общая проблема столбцовых СУБД – медленный INSERT (заливать данные нужно будет пакетами, используя BULK INSERT). Также стоит упомянуть отсутствие транзакций, работу только под Linux и разницу в движках таблиц.
ClickHouse и 1С
Приведем в пример все тот же журнал регистрации, претерпевший изменения формата. Новый его вариант дает возможность для довольно эффективного чтения данных, но когда система делает в него записи, пользователям приходится ждать из-за блокировок. То есть работа более ли менее приемлемой будет только в небольшой базе. В обратном случае придется использовать старый формат, но из него можно получить данные только за последний день. Быстро собрать данные для анализа логов и формирования любых статистических показателей из этого же объемного журнала регистрации как раз поможет ClickHouse.
Помимо этого с помощью ClickHouse можно анализировать любые операции, вести в 1С статистику работы пользователя (или KPI), а также справляться с бизнес-задачами, например, получить отчет «Динамика остатков».
Хотя отчет «Динамика остатков» и не относят к «большим данным», представим, что по 60 тысячам позициям номенклатуры, «разложенным» по 200 складам (небольшой объем для обычной торговой компании), нам нужно проанализировать динамику остатков по каждой номенклатуре, на каждом складе, за каждый день в течение последних пяти лет. В этом случае мы будем работать с 22 миллиардами записей. ClickHouse позволит отслеживать в базе в режиме on-line как текущие остатки, которые туда регулярно подгружаются (настроен интервал обновления данных в 5 минут),так и исторические данные за предыдущие 10-20 лет. При этом данные обрабатываются быстро, и более того – их становится меньше за счет сжатия.
Установка ClickHouse
Качаем готовый образ и разворачиваем его на виртуалке (или устанавливаем сами):
https://www.osboxes.org/ubuntu/
Скачиваем установочный файл ClickHouse из репозитория:
clickhouse.tech/docs/ru/getting-started/И обновляем:
deb http://repo.yandex.ru/clickhouse/trusty stable main
sudo apt-get update
sudo apt-get install clickhouse-client clickhouse-server-common
Стартует сервис
sudo service clickhouse-server start
Проверяете его работу через HTTP-интерфейс:
https://<Адрес сервера>:8123/
из мира 1С для ИТ-Директоров
Создание таблицы
Примерный вид команды по созданию таблицы из командной строки:
CREATE TABLE EventLog
(
RowID Ulnt32,
DataBaseName String,
EventDate Date,
EventDateTime DateTime,
Severity Ulnt8,
UserCode String,
User String,
App String,
Computer String,
Event String,
Comment String,
Metadata String,
DataPresentation String,
DataType Int32)
ENGINE=MergeTree(EventDate,(RowID,DataBaseName,
EventDate,EventDateTime),8192);
Синтаксис команды стандартный (как в SQL CREATE TABLE), но стоит обратить внимание на ENGINE=MergeTree – «движок таблицы». Разработчики при массовой загрузке рекомендуют загрузить данные сначала в движок Log, а после внутри ClickHouse преобразовывать в MergeTree.
Параметры при создании:
- Столбец с датой;
- Первичный ключ;
- Третий параметр очень специфичен, и его лучше не менять.
Создать таблицу можно как программу или из командной строки.
Взаимодействие с ClickHouse
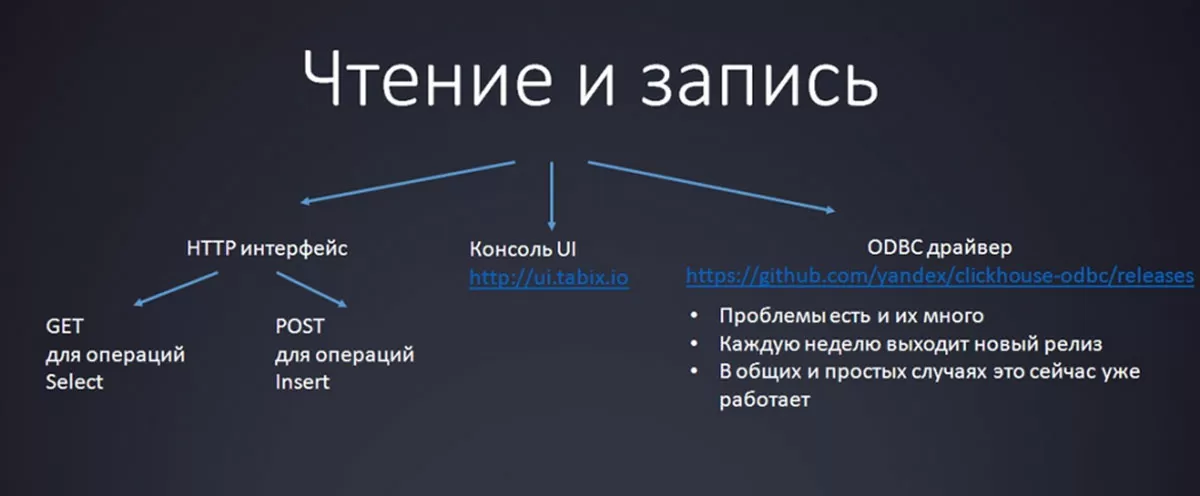
Для чтения и записи в ClickHouse предусмотрен ODBC-драйвер, но пока он подходит для весьма ограниченного спектра задач, поскольку находится на стадии активного развития. Например, с его помощью можно наладить интеграцию с Excel, но подключиться к 1С как внешний источник через него пока не получается.
UI-консоль на JavaScript позволит довольно быстро начать работу: надо перейти по ссылке ui.tabix.io, ввести свои настройки подключения и приступить к работе.
Универсальный кроссплатформенный HTTP-интерфейс имеет стандартную логику и в работе не должен вызвать затруднений: для операций SELECT используют простые GET-запросы, для INSERT* – чуть более сложные POST-запросы.
*INSERT правильнее делать через BULK INSERT.
Обращение к ClickHouse из 1С
Пример кода на 1С:
GET:
http://127.0.0.1:8123/?query=select * from EventLog
Соединение = Новый HttpСоединение(“127.0.0.1”, “8123”);
HTTPЗапрос = Новый HTTPЗапрос(“?query=select * from EventLog”);
Результат = Соединение.Получить(HTTPЗапрос);
ТекстОтвета = Результат.ПолучитьТелоКакСтроку();
POST:
Соединение = Новый HttpСоединение(“192.168.17.129”, “8123”);
ФайлЗапроса = ПолучитьИмяВременногоФайла();
ТекстовыйФайл = Новый ТекстовыйДокумент();
ТекстовыйФайл.УстановитьТекст(“INSERT INTOt VALUES(5),(6),(7)”);
ТекстовыйФайл.Записать(ФайлЗапроса,КодировкаТекста.ANSI);
HTTPЗапрос = Новый HTTPЗапрос();
HTTPЗапрос.УстановитьИмяФайлаТела(ФайлЗапроса);
Результат = Соединение.ОтправитьДляОбработки(HTTPЗапрос);
Для данного примера характерны те же моменты, что и для HTTP-соединения из 1С:
- GET-запрос для SELECT – Соединение.Получить().
- POST-запрос для INSERT – Соединение.ОтправитьДляОбработки().
POST дан для примера, поскольку реально для загрузки сотни гигабайт потребуется команда BULK INSERT: команды будут похожи, но нужно будет сформировать CSV-файл для передачи в ClickHouse. То есть парсинг того же многогигабайтного журнала регистрации производится не в 1С, а в стороннем приложении, оттуда и будет исходить BULK INSERT. А из 1С после можно обращаться к ClickHouse и строить отчеты на основе его данных, для чего предназначен и HTTP-интерфейс.
консультация эксперта

самые свежие новости 1 раз в месяц


