- Блокировки в 1С 8.3: поиск и устранение в коде, перевод на управляемые блокировки
- 1С Управляемые блокировки
- Использование объектов DMO SQL-сервера
- Определение проблемных запросов в результате сбора Data Collector
- Оптимизация запросов как возможность ускорить 1С 8.3
- Использование индексов и их влияние на качество производительности системы
Во многом оптимизация 1С и скорость работы зависит от работы с блокировками, запросами и индексами. Постараемся ответить на вопрос «как ускорить работу 1С» (вопрос, как ускорить запуск 1С, мы рассмотрим в другой статье) и избежать жалоб пользователей на «долгое проведение документов», которое неминуемо сказывается на бизнес-процессах.
Содержание статьи:
Часть 1. Ускорение 1С
- Блокировки в 1С: поиск и устранение в коде, перевод на управляемые блокировки
- 1С Управляемые блокировки
- Использование объектов DMO SQL-сервера
- Определение проблемных запросов в результате сбора Data Collector
Часть 2. Оптимизация 1С
Часть 3. Производительность 1С
Блокировки в 1С 8.3: поиск и устранение в коде, перевод на управляемые блокировки
Блокировки являются частью механизма ACID. Рассмотрим его концепцию, представленную в виде упрощенной схемы, на примере SQL SERVER
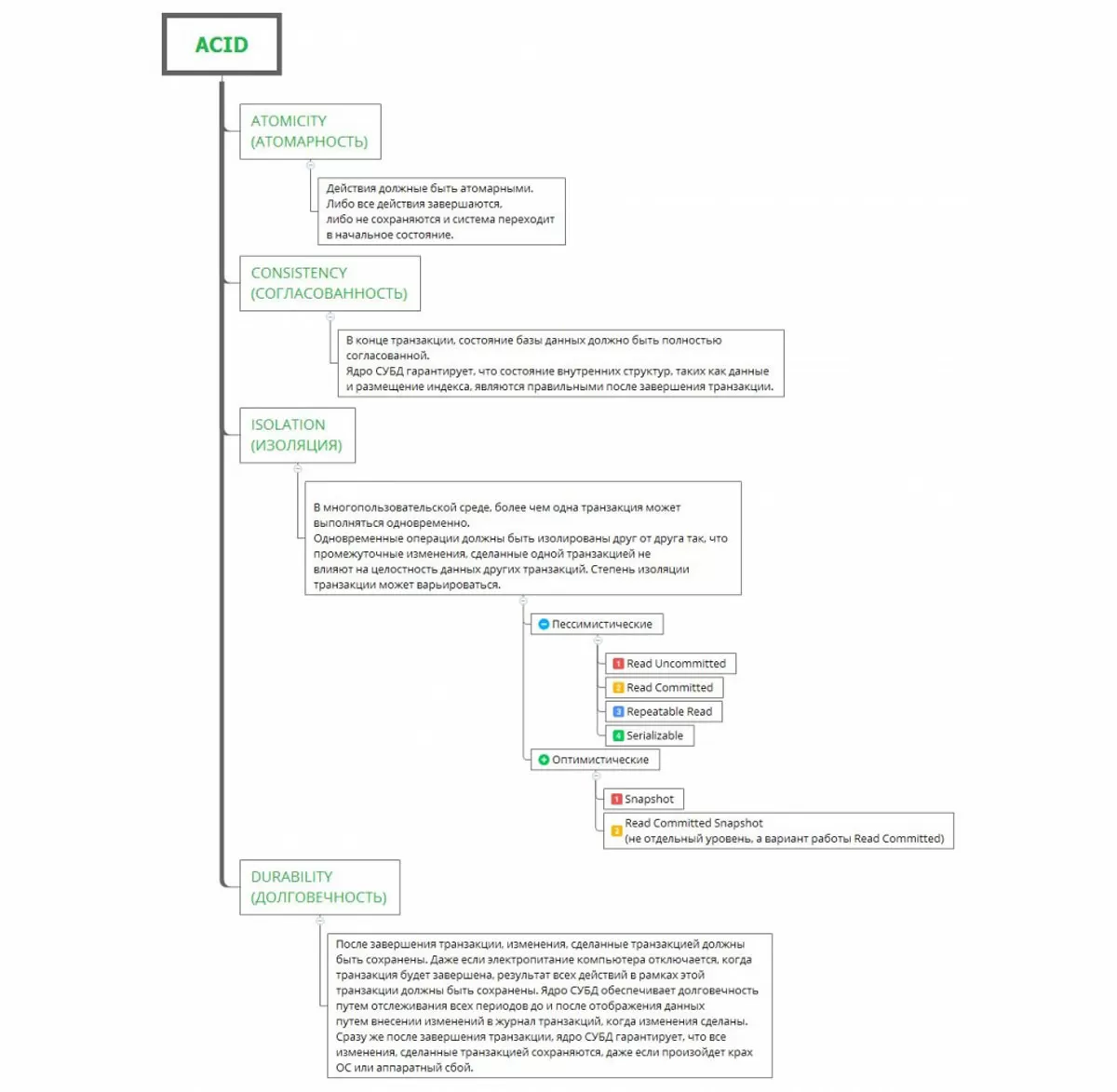
В автоматическом режиме управление блокировками осуществляется самой СУБД. При этом на MS SQL сервере появлялись такие побочные эффекты, как блокировки пустых таблиц и приграничного диапазона данных (уровень Serializable), что создавало дополнительные проблемы в многопользовательской работе. Для решения этих проблем фирма 1С создала управляемые блокировки.
1С Управляемые блокировки
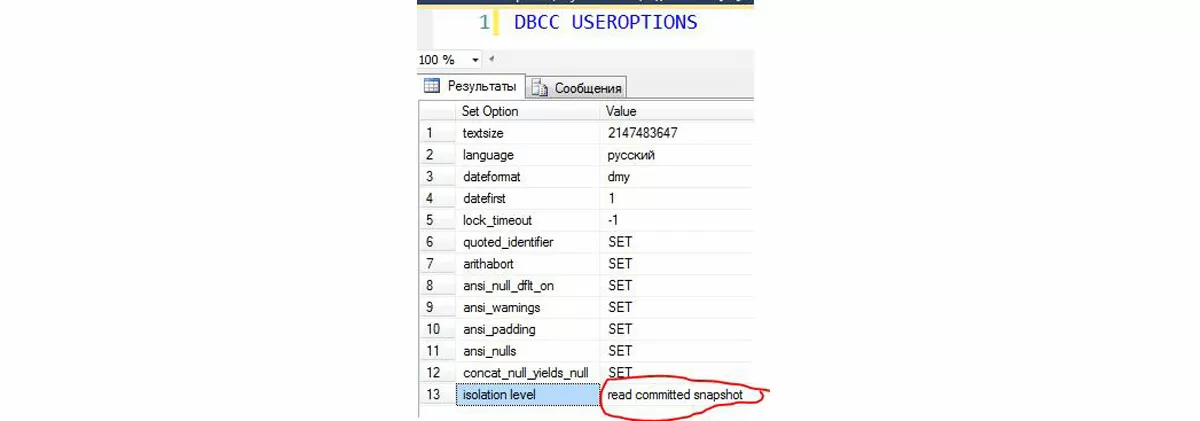
Механизм блокировок был вынесен на сервер 1С, а на уровне СУБД изоляция снизилась до минимума. На MS SQL уровень изоляции был понижен до Read Committed с механизмом разделяемых блокировок на платформе 8.2 и механизмом версионирования строк на платформе 8.3 (так называемый Read Committed Snapshot Isoliation). Точнее, это одноименное свойство базы данных и два режима работы Read Committed, зависящие от этого параметра.
При последнем уровне изоляции (RCSI), механизм позволил не пересекаться на сервере СУБД читающих и пишущих транзакций по одним и тем же ресурсам. Всю основную работу на себя взял сервис блокировки 1С, определяющий на основании родных метаданных, пускать или не пускать транзакции на сервер СУБД, чтобы не происходило нарушений бизнес-логики. Проблемы с блокировками пустых таблиц и приграничных диапазонов ушли в прошлое.
| СУБД | Вид блокировки | Уровень изоляции транзакций | Чтение вне транзакции |
|---|---|---|---|
| Автоматические блокировки | |||
| Файловая База Данных | Таблиц | Serializable | Dirty read |
| MS SQL Server | Записей | Repetable Read или Serializable | Dirty read |
| IBM DB2 | Записей | Repetable Read или Serializable | Dirty read |
| PostgreSQL | Таблиц | Serializable | Consistent reading |
| Oracle Database | Таблиц | Serializable | Consistent reading |
| Управляемые блокировки | |||
| Файловая База Данных | Таблиц | Serializable | Dirty read |
| MS SQL Server 2000 | Записей | Read Commited | Dirty read |
| MS SQL Server 2005 и выше | Read Commited Snapshot | Consistent reading | |
| IBM DB2 до версии 9.7 | Записей | Read Commited | Dirty read |
| IBM DB2 версии 9.7 и выше | Записей | Read Commited | Consistent reading |
| PostgreSQL | Записей | Read Commited | Consistent reading |
| Oracle Database | Записей | Read Commited | Consistent reading |
Для того чтобы узнать, в каком режиме блокировок находится база программы 1С, необходимо выполнить следующий запрос из SSMS в контексте нужной базы:
Блокировки 1С. Пользователь не будет ждать на блокировках, произойдет ускорение работы 1С, если придерживаться определенных правил:
- Продолжительность транзакций должна быть максимально сокращена по времени. Проведение в транзакции длительных расчетов в 100% случаев приведет к блокировке при работе на OLTP системе.
- Исключены длительные внешние операции в рамках транзакции, например, отправка и принятие подтверждений по электронной почте, работа с файловой системой и другие дополнительные действия. Все операции должны быть вынесены в отложенные короткие задания.
- Максимально оптимизированы запросы.
- Создание индексов должно производиться только по мере необходимости, для обеспечения оптимальной производительности запросов в пределах приложения.
- Минимизированы включения в кластерный индекс часто обновляемых столбцов. Обновления столбца/ов кластерного ключа индекса требует блокировки, как на кластерном индексе, так и на всех некластеризованных индексах (так как их строка-локатор содержит ключ кластерного индекса).
- По возможности создан и используется покрывающий индекс для сокращения времени выборки данных.
- Использование самого низкого уровня изоляции транзакциями, что потребует перехода на режим управляемых блокировок.
Инструменты для диагностики блокировок:
- Технологический журнал;
- Центр управления производительностью из инструментария 1С;
- Облачные сервисы Гилева;
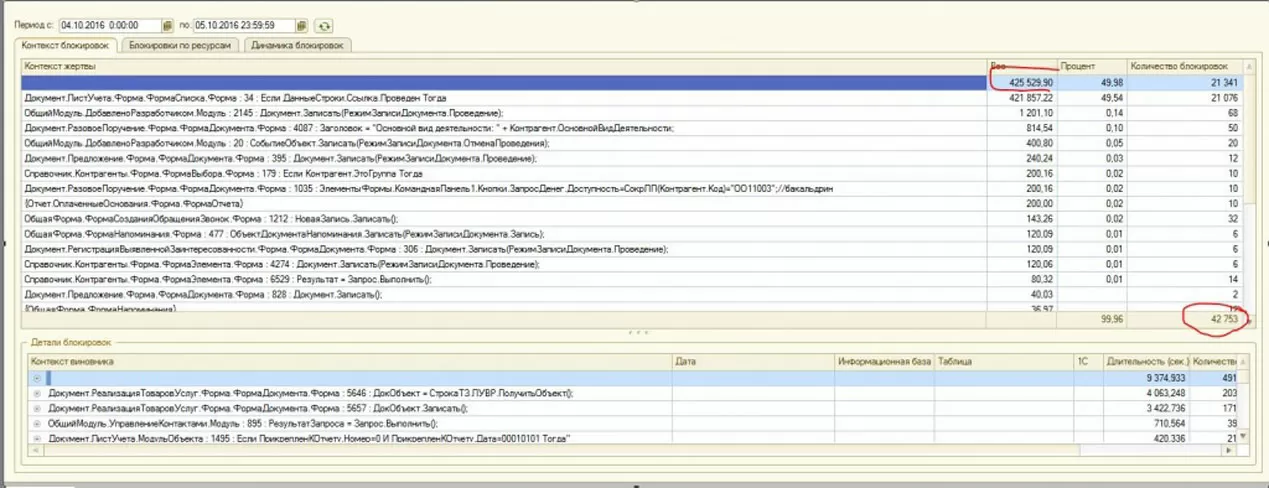
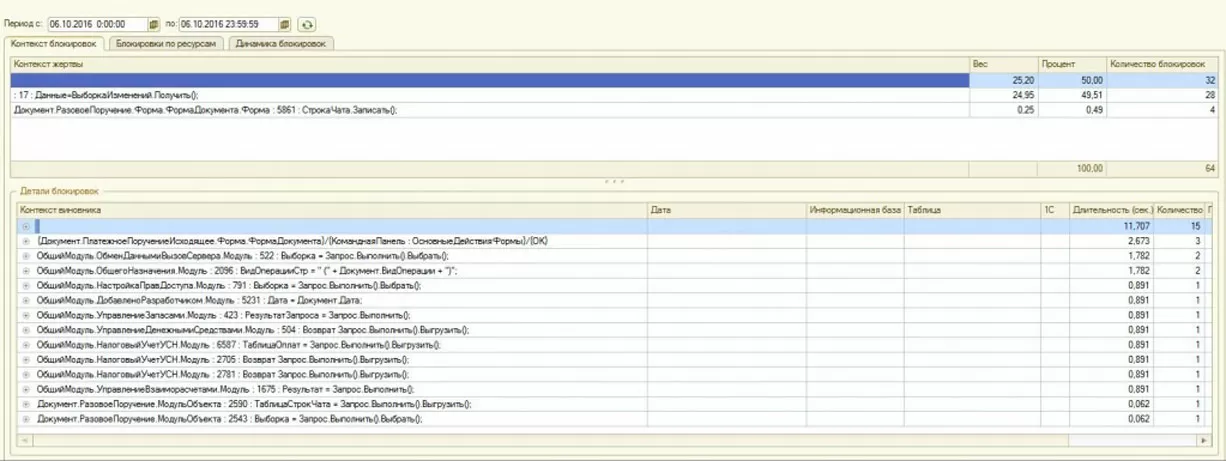
Ниже приведен пример мониторинга системы сервисом Гилева. Общая длительность блокировок ~15 часов. Более 400 активных пользователей. После принятия решений и оптимизации – время таймаутов меньше минуты, а количество блокировок сократилось в ~670раз.
Было:
Стало:
В ситуации, когда «все висит и долго проводиться», а сервисы мониторинга не настроены или не используются совсем, помня принцип Парето, необходимо сосредоточить внимание на коде.
В автоматическом режиме наличие блокировок на сервере можно обнаружить с помощью системной процедуры в контексте нужной базы. Данная хранимая процедура позволяет определить, в каком режиме работают блокировки, их статус, тип и прочее:
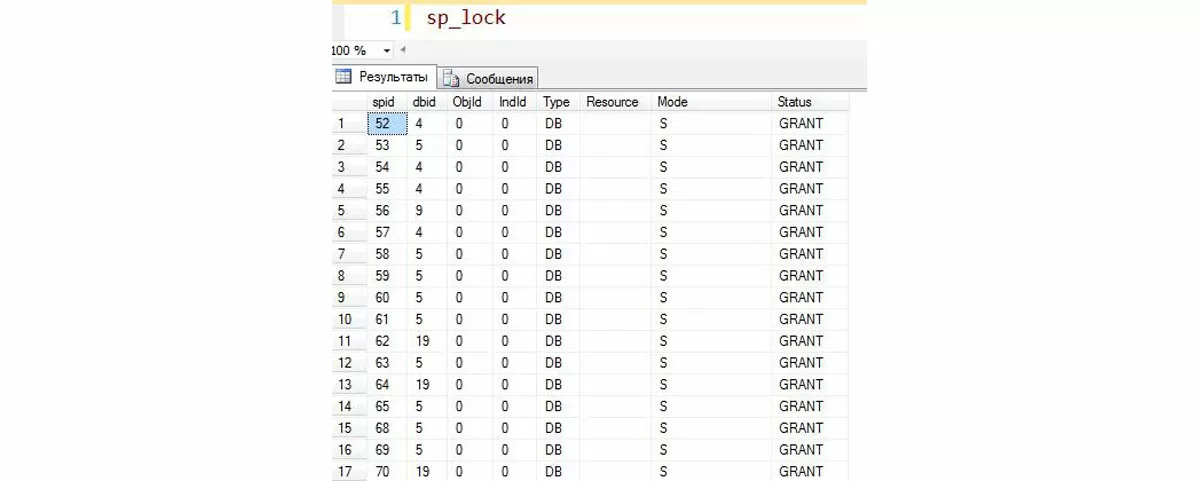
Доработав процедуру под 1С, можно получить наглядную информацию о том, что происходит в данный момент на сервере, с учетом специфики таблиц 1С:
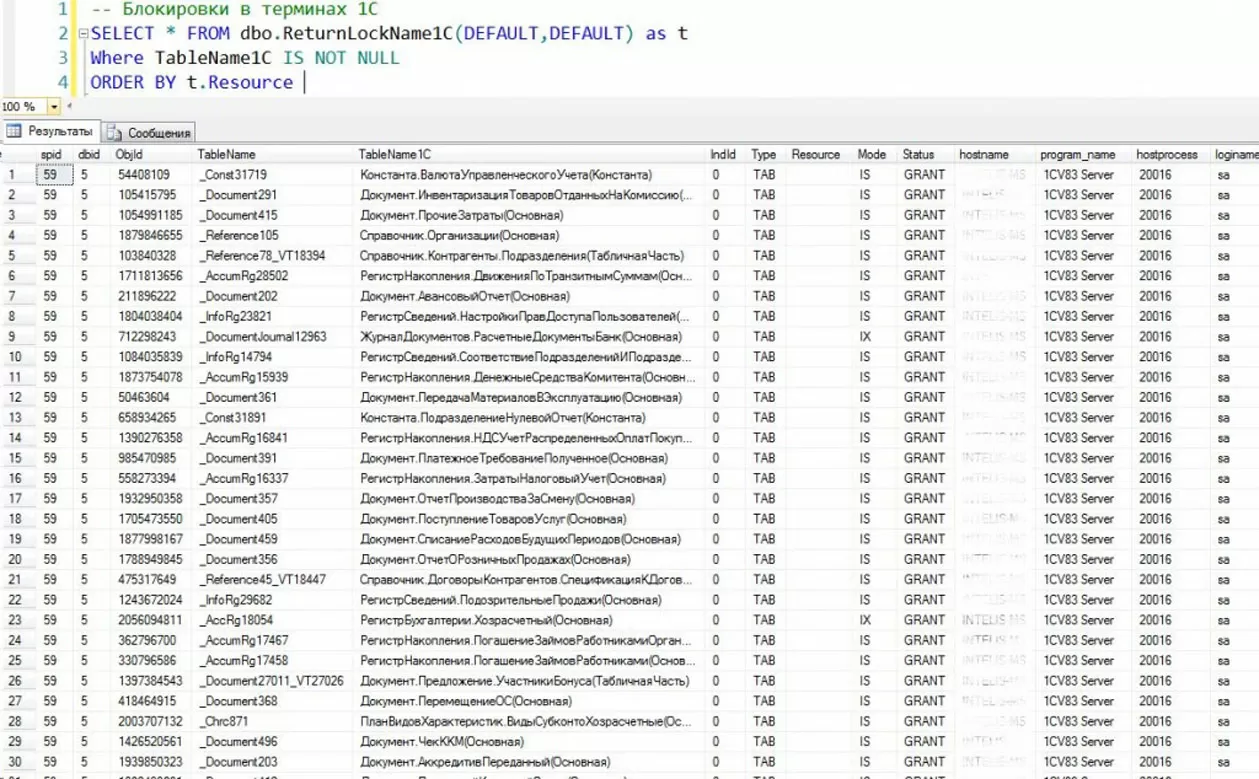
Фрагмент 1
//Блокировки в терминах 1С
SELECT * FROM dbo.ReturnLockName1С(DEFAULT,DEFAULT) as t
Where TableName1С IS NOT NULL
ORDER BY t.Resource
Применение данного механизма позволяет получить полную информацию об имеющихся блокировках на текущий момент. Если в отчете одни S-блокировки, проблема может заключаться в длительном запросе или запросах. Для установления причины и места их появления в коде можно пойти разными путями: использовать объекты DMO SQL-сервера (но учитываем, что данные из них сбрасываются после перезагрузки сервера) или настроить Data Collector, сохранив данные мониторинга в таблицах на определенное время. Главное, получить тексты проблемных запросов.
Использование объектов DMO SQL-сервера
Выводим дату старта сервера для понимания актуальности данных. Разбиваем пакет по рейтингу чтения (физического, логического, нагрузке на процессор). В этом случае используются основные данные из sys.dm_exec_query_stats. Текст запроса переводим в термины 1С. Если по тексту запроса можно понять контекст вызова, то осталось посмотреть план запроса, найти проблемные операторы и понять, что можно сделать.
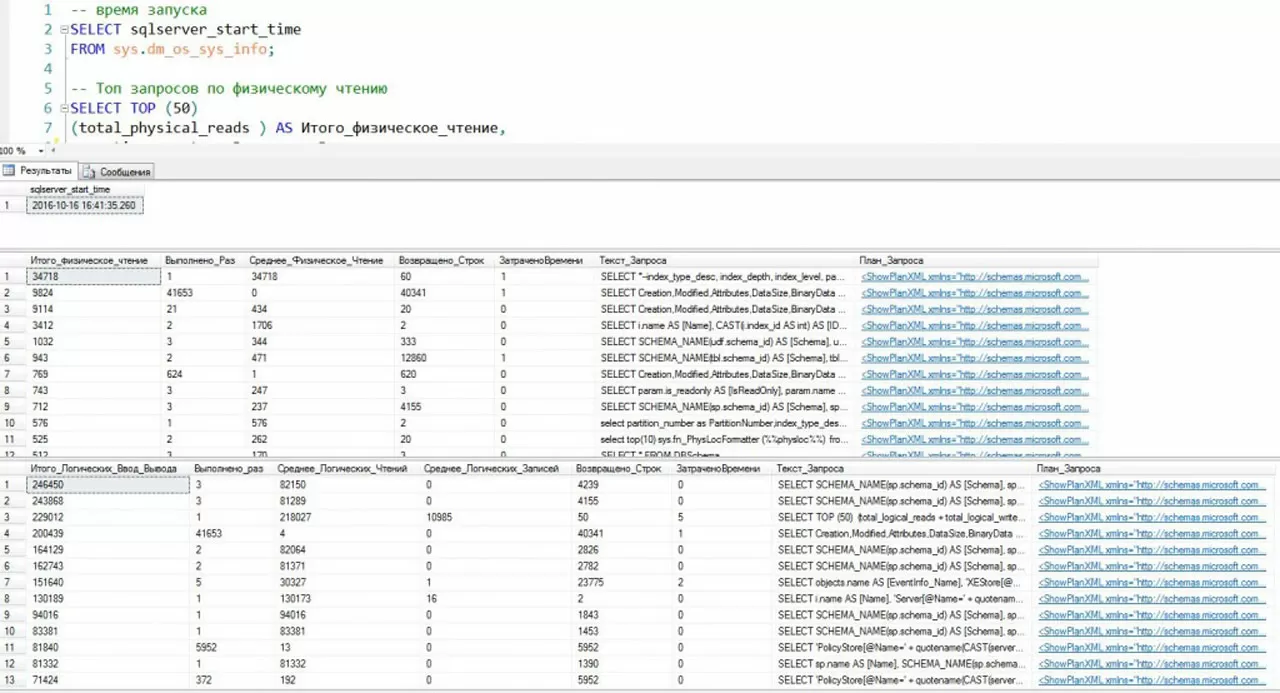
Фрагмент 2
//время запуска
SELECT sqlserver_start_time
FROM sys.dm_os_sys_info;
//Toп запросов no физическому чтению
SELECT TOP (50)
(total_physical_reads ) AS Итого_физическое_чтение,
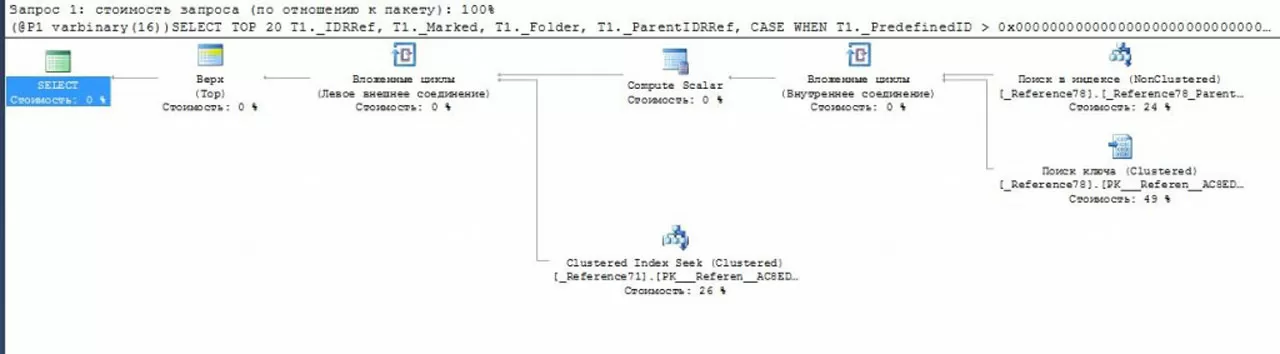
Определение проблемных запросов в результате сбора Data Collector
С помощью этого инструмента можно ранжировать данные по необходимым параметрам, таким как загрузка процессора, длительность, операции логического ввода/вывода, физического чтения, что позволяет сохранить полную статистику для дальнейшего анализа, несмотря на перезагрузку сервера SQL.
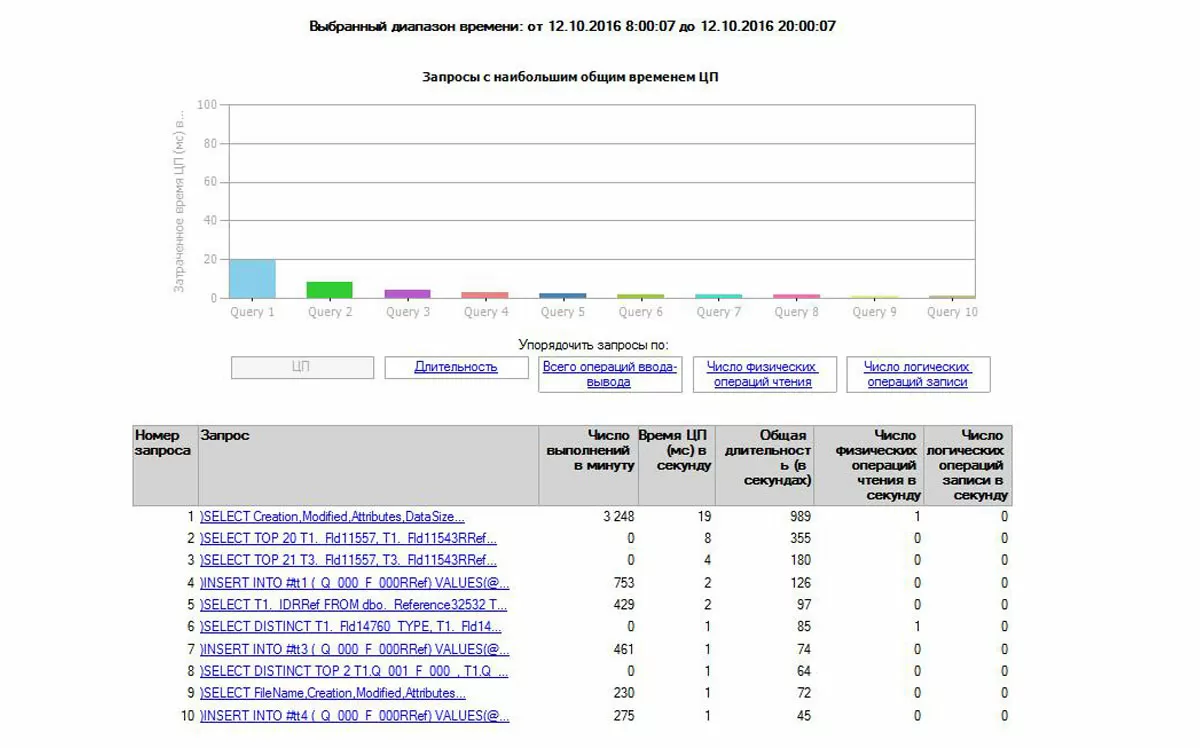
После того, как проблемные запросы собраны сервером без сторонних мониторингов, можно составить рейтинг полученных данных по необходимым параметрам.
Далее, включив технологический журнал и указав в настройках «поиск по строке» и часть запроса, которая гарантированно будет встречаться, можно выяснить, откуда вызван проблемный запрос. Если на сервере имеется несколько баз или известно имя пользователя, стоит добавить дополнительные поля для фильтра, чтобы снизить нагрузку на сервер при сборе технологического журнала.
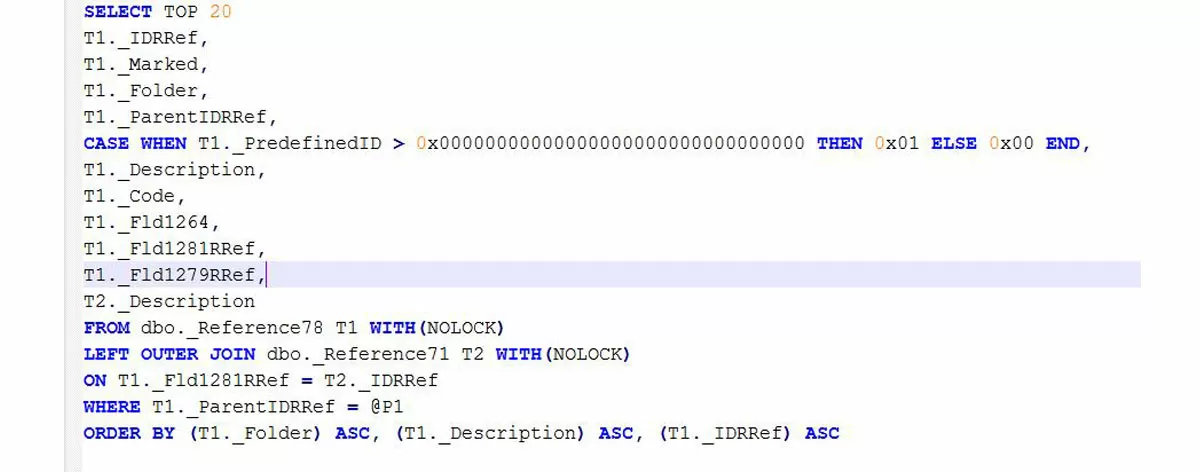
Пример проблемного запроса и образец настройки технологического журнала:

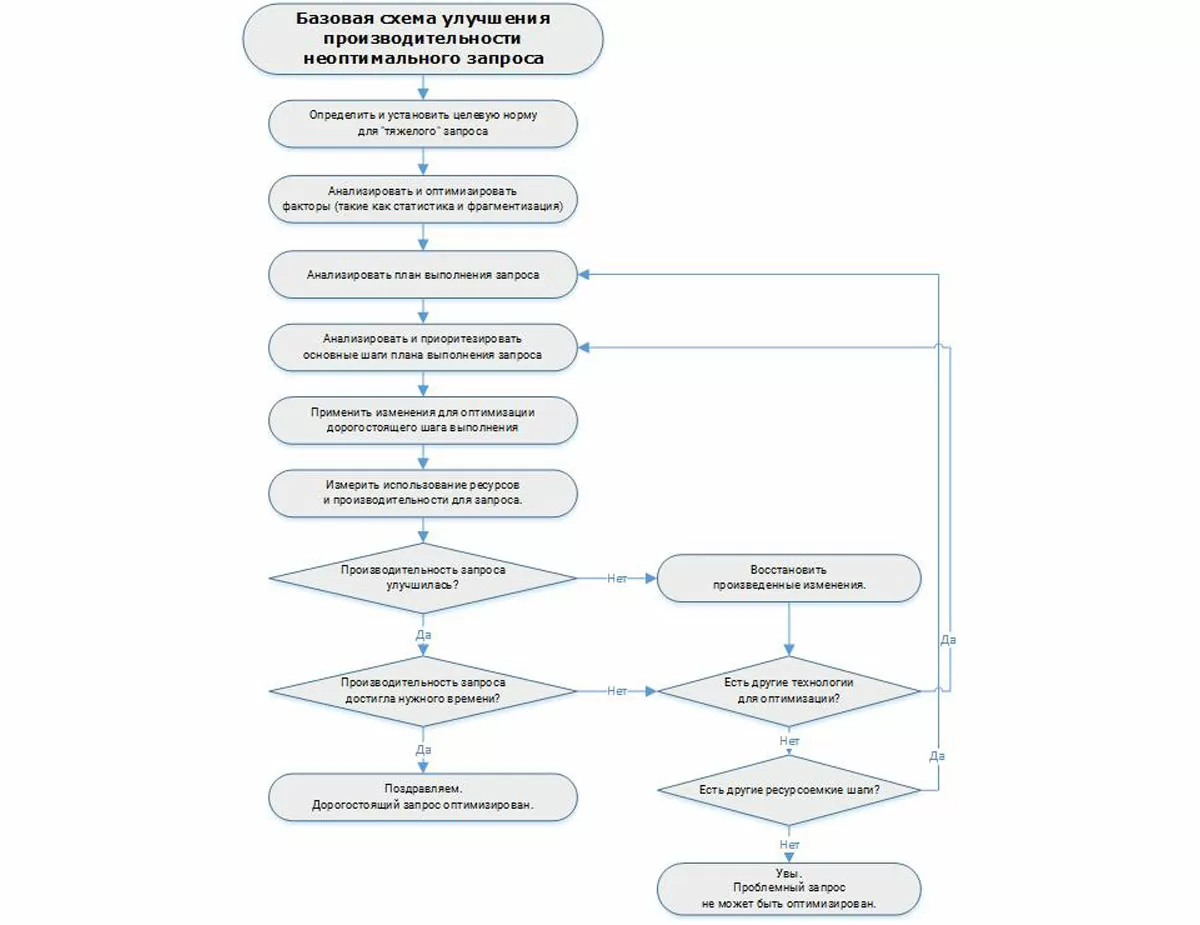
Оптимизация запросов как возможность ускорить 1С 8.3
Рассмотрим основные рекомендации, соблюдение которых позволит увеличить скорость работы 1С путем уменьшения проблем в написании запросов.
Последствия неоптимальных запросов могут проявляться в виде длительных проведений документов, мучительно долгого формирования отчетов, «зависания» системы и прочих неприятных событий.
При работе с запросами НЕЛЬЗЯ:
- Соединять таблицы с подзапросами;
- Соединять обычные таблицы с виртуальными;
- Использовать логического «ИЛИ» в условиях;
- Использовать подзапросы в условиях соединения;
- Получать данные через точку от полей составного типа без ключевого слова «Выразить».
При работе с запросами МОЖНО:
- Создать индексы в условиях запроса, полях соединения, агрегации и сортировки;
- Фильтрацию виртуальных таблиц необходимо производить с использованием параметров отбора.
из мира 1С для ИТ-Директоров
Использование индексов и их влияние на качество производительности системы
Очень много написано про индексы, о необходимости их использования и влияние на качество работы системы. Постараемся разобраться в тонкостях «устройства» индексов, вариантах применения и преимуществах перед обычными таблицами.
Индексирование является важной частью ядра СУБД. Отсутствующие индексы, или наоборот, их излишнее количество, влияют на скорость выборки, модификацию, добавление и удаление данных. Рассмотрим индексирование на примере наиболее распространенной СУБД компании Microsoft.
Для общего понимания, как это работает, рассмотрим подробности устройства механизмом хранения данных, которые мы обычно представляем в виде таблицы (например, Excel).
Единицей физического хранения данных является страница — модуль размером в 8 Кбайт, принадлежащий только одному объекту (например, таблице или индексу). Страница является наименьшей единицей для чтения и записи. Страницы собраны в экстенты. Экстент состоит из 8 последовательных страниц. Страницы экстента могут принадлежать как одному, так и нескольким объектам. Если страницы принадлежат нескольким объектам, экстент называется «смешанным».
Заголовок страницы (первые 96 байт) состоит из разных флагов, которые использует в работе ядро СУБД. Ее содержимое можно посмотреть ниже:
Строки с данными (8060 байт):

Таблица смещения (36 байт):

Получив представление, как устроена единица хранения данных на диске, поговорим подробнее о таблицах и индексах.
По умолчанию, если не использовать специальных операторов T-SQL, пустая таблица создается в виде «кучи» – простого набора страниц и экстентов. Данные в «куче» не имеют никакого логического порядка. Ядро SQL Server отслеживает принадлежность страниц и экстентов к определенному объекту с помощью специальных системных страниц, называемых «картами распределения индекса» (Index Allocation Map). Каждая таблица или индекс имеет по крайней мере одну страницу IAM, называемую «первой страницей IAM».
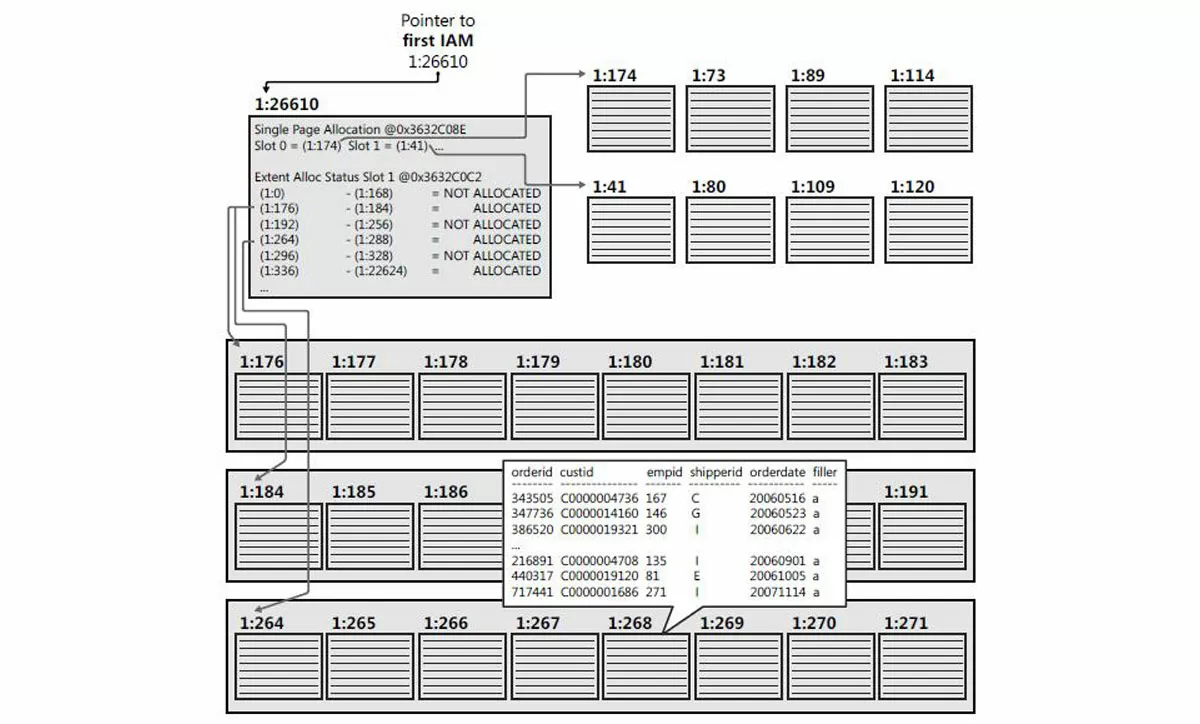
Таким образом, после создания обычной таблицы, по умолчанию, получается хаотичное расположение данных. Посмотреть статус таблицы можно с помощью следующей процедуры:

Основные индексы, которые использует платформа 1С
Фрагмент 3
SELECT NAME, TYPE, TYPE_DESC FROM sys.indexes WHERE object_id = OBJECT_ID('ДанныеТрассировки')
Мифы и реальность:
Миф первый: кластерные индексы и таблица данных – это две разные сущности, хранящиеся отдельно друг от друга.
Миф второй: кластерных индексов в одной таблице может быть много.
Скачал программу для оптимизации СУБД. Создал рекомендованные индексы. Скорость выборки увеличилась на 50%. Изменение и добавление данных замедлилось в 7раз.
Кластеризованный (кластерный) индекс
Кластеризованные индексы представляют собой набор страниц, которые сортируют и хранят строки данных в таблицах или представлениях на основе их ключевых значений – столбцов, включенных в определение индекса. Существует ограничение на данный вид индексов в 16 столбцов и 900 байт. Для каждой таблицы существует только один кластеризованный индекс, потому что строки данных могут быть отсортированы только в одном порядке. Создание кластеризованного индекса происходит посредством реорганизации таблицы, а не копирования данных, что дает возможность сохранить таблицу в виде сбалансированного дерева.
После добавления кластерного индекса таблица данных трансформируется:

Фрагмент 4
SELECT NAME, TYPE, TYPE_DESC FROM sys.indexes WHERE object_id = OBJECT_ID('ДанныеТрассировки')
Некластеризованный индекс
Некластеризованные индексы имеют структуру отдельную от строк данных. В некластеризованном индексе содержатся значения ключа кластерного индекса, и каждая запись содержит ключ кластеризованного индекса (не RID, т.к. таблицы 1С не используют кучи, за редким исключением).
Можно добавить неключевые столбцы на конечный уровень некластеризованного индекса и обойти существующее ограничение на ключи индексов (900 байт и 16 ключевых столбцов), выполняя полностью индексированные запросы.
После добавления некластерного индекса, произошло копирование данных, и появился еще один объект:

Фрагмент 5
SELECT NAME, TYPE, TYPE_DESC FROM sys.indexes WHERE object_id = OBJECT_ID( 'ДанныеТрассировки')
Схема кластерного индекса после получения его из кучи в виде сбалансированного дерева:
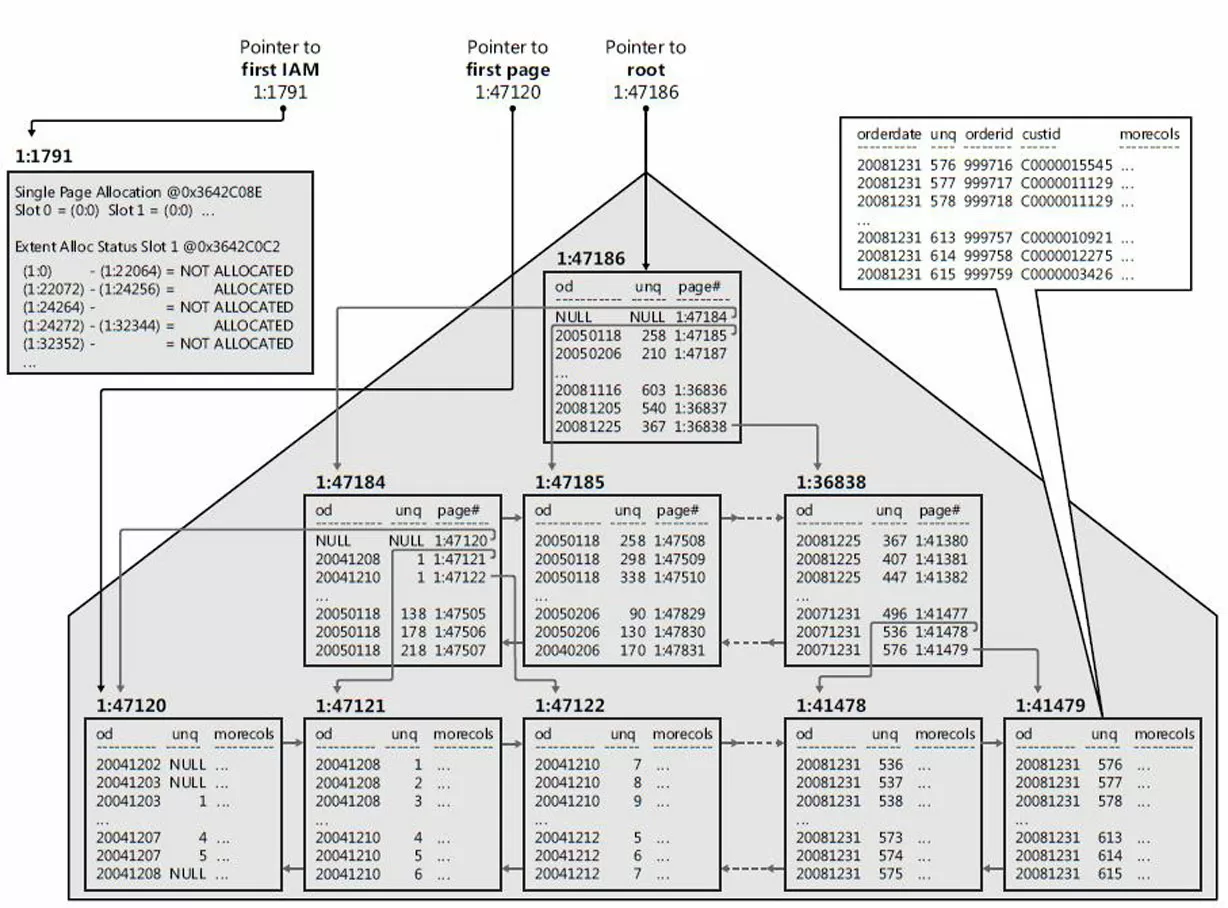
Схема некластерного индекса, полученного из кластерной таблицы (обратите внимание, столбец row locator имеет ключ кластерного индекса):
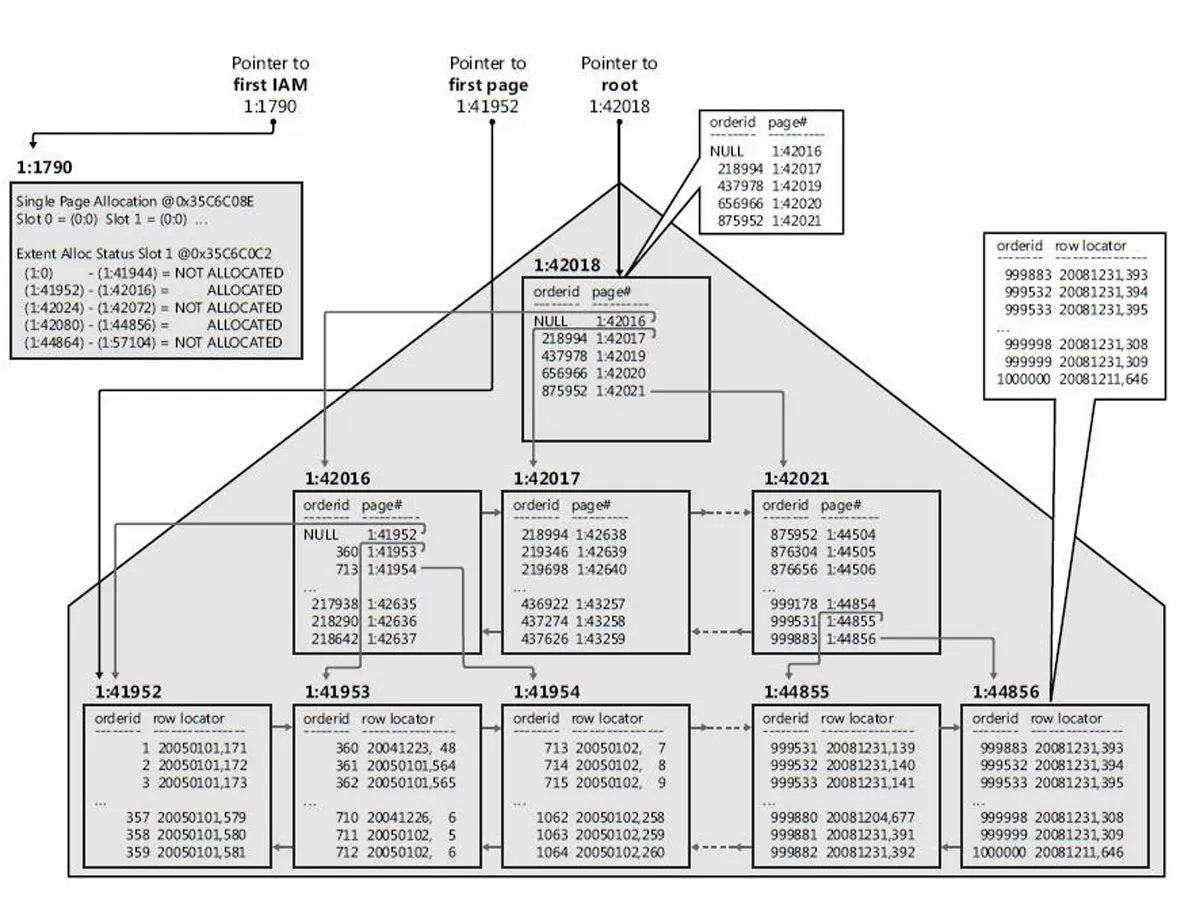
Влияние индексов на производительность запросов
Оптимизатор запросов, используя индекс, выполняет поиск по ключевым столбцам индекса, находит место хранения запрашиваемых строк и извлекает оттуда совпадающие строки. Поиск по индексу протекает намного быстрее, чем поиск по таблице, так как в отличие от таблицы, индекс часто содержит меньшее количество столбцов в каждой строке, а строки отсортированы по порядку.
Создание множества индексов приводит к тому, что скорость выборки увеличивается, а скорость записи при модификации существенно снижается. Для решения этой проблемы, в первую очередь, необходимо удалить ненужные индексы или предварительно заблокировать их не удаляя, что позволит просто включить их, в случае возникновения такой надобности.
Обратим внимание, что кластерный индекс блокировать ни в коем случае нельзя, т.к. это закроет доступ к данным таблицы. Это относится только к тем индексам, которые вы создали самостоятельно, через T-SQL. Причина создания индексов средствами T-SQL, минуя «1С:Предприятия», связана, в первую очередь, с ограниченными возможностями платформы 1С в части манипуляции индексами и включения в созданный/емый индекс дополнительных полей.
Инструкция T-SQL, которая выполняет действие по блокированию индекса:
//Блокируем отдельный индекс в таблице
-ALTER INDEX _Reference22_ByPredefinedIDNotUniq ON _Reference22
DISABLE;
//Включаем нужный индекс
-ALTER INDEX _Reference22_ByPredefinedIDNotUniq ON _Reference22
REBUILD;
Помимо вышеописанных действий, важно создать файловую группу на физическом диске, на котором не располагаются текущие файлы базы данных, и перенести туда некластерные индексы. Это позволит ускорить модификацию данных за счет распараллеливания их записи.
Определение необходимых или лишних индексов для ускорения выполнения запросов
По умолчанию 1С создает определенный базовый набор индексов. Зачастую, их просто не хватает. SQL-сервер имеет механизмы, которые позволяют понять на основании рабочей нагрузки, насколько необходимы имеющиеся индексы.
Помощник по настройке ядра СУБД (Database Engine Tuning Advisor) анализирует базы данных и составляет рекомендации по оптимизации производительности запросов. Его можно использовать для выбора и создания оптимальных наборов индексов, не обладая экспертным уровнем понимания структуры баз данных или внутренних процессов SQL Server. Помощник по настройке ядра СУБД позволяет выполнять следующие задачи:
- Устранение неполадок производительности конкретного проблемного запроса;
- Настройка большого набора запросов в одной или нескольких базах данных.
Объекты DMO (dynamic management objects), к которым относятся динамические административные представления и функции динамического управления. Например, инструкцией T-SQL можно получить все индексы, которые не использовались с момента последнего запуска сервера.
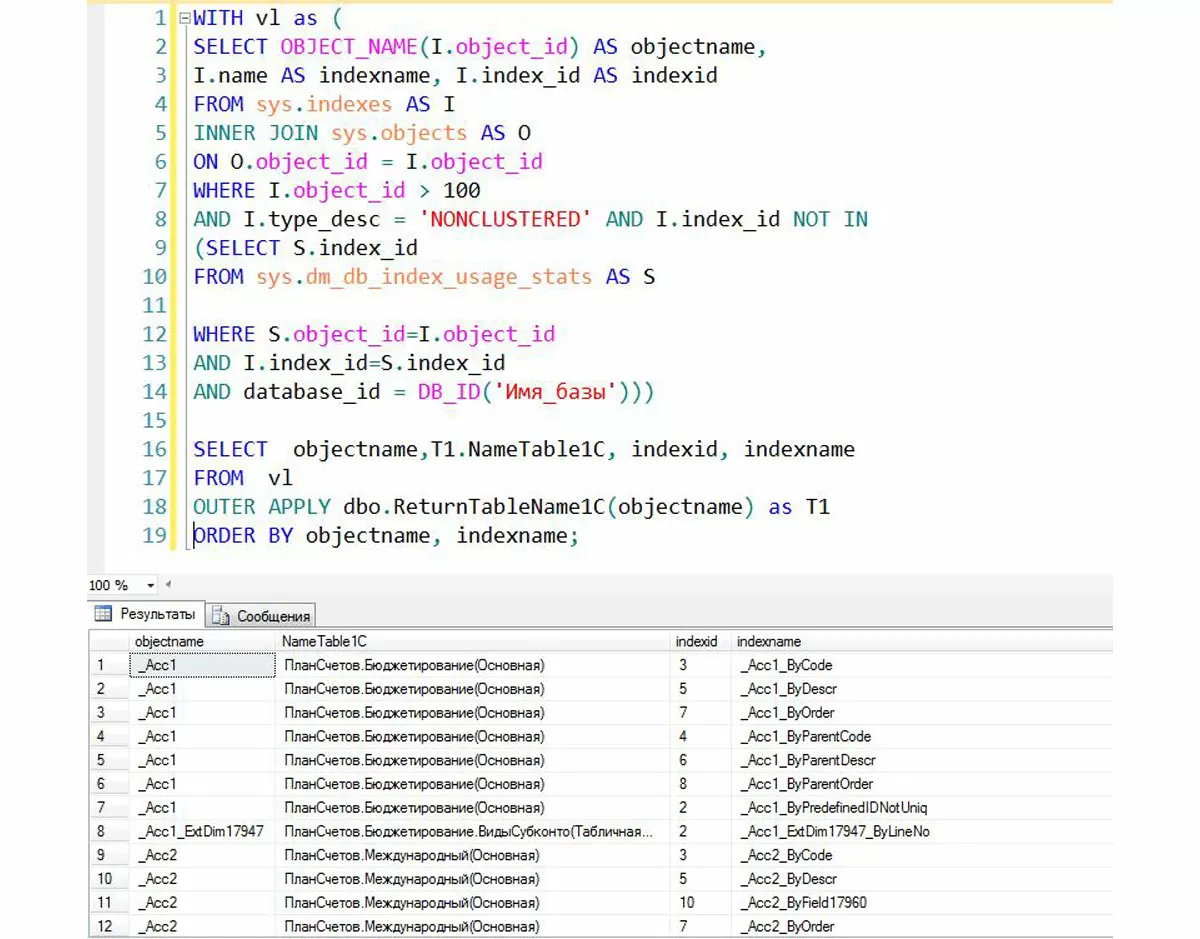
Фрагмент 6
WITH vl as (
SELECT OBJECT_NAME(I.object_id) AS objectname,
I.name AS indexname, I.index_id AS indexid
FROM sys.indexes AS I
INNER JOIN sys.objects AS O
ON O.object_id = I.object_id
WHERE I.object_id > 100
AND I.type_desc = 'NONCLUSTERED' AND I.index_id NOT IN
(SELECT S.index_id
FROM sys.dm_db_index_usage_stats AS S
WHERE S.object_id=I.object_id
AND I.index_id=S.index_id
AND database_id = DB_ID('Имя_базы’)))
SELECT objectname,T1.NameTable1С, indexid, indexname
FROM vl
OUTER APPLY dbo.ReturnTableName1С(objectname) as T1
ORDER BY objectname, indexname;
Инструкция, с помощью которой можно создавать необходимые индексы, которые рекомендует ядро СУБД:
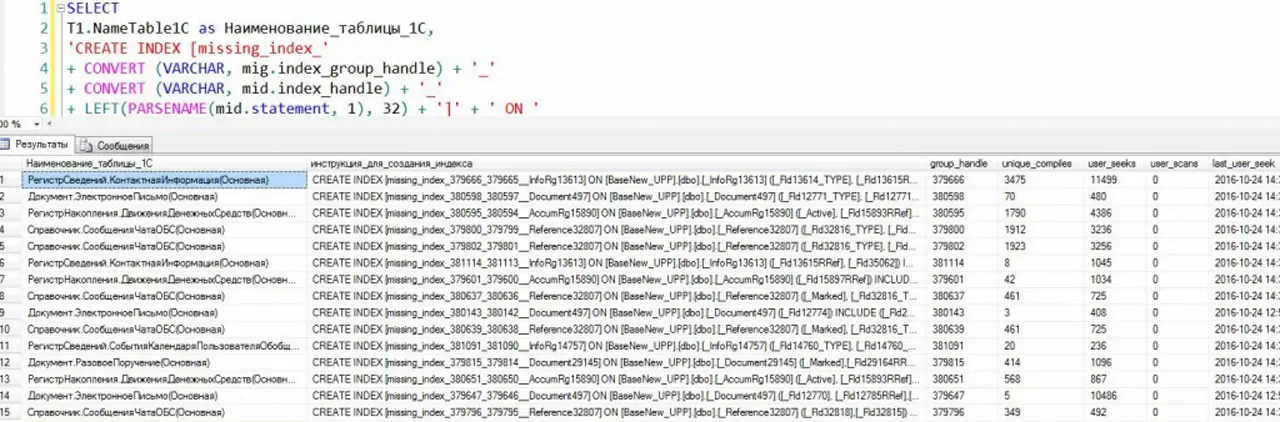
Фрагмент 7
SELECT
T1.NameTable1С as Наименование_таблицы_1С,
'CREATE INDEX [missing_index_'
+ CONVERT (VARCHAR, mig.index_group_handle) + '_'
+ CONVERT (VARCHAR, mid.index_handle) + '_'
+ LEFT(PARSENAME(mid.statement, 1), 32) + ']' + ' ON '
Оптимизатор запросов во время генерации плана выполнения запроса выявляет необходимость создания недостающего индекса. Эту информацию он сохраняет в XML ShowPlan. Т.к. планы запросов хешируются и инструкции сохраняются (до следующего перезапуска сервера), то их можно извлечь, обработать и получить готовые инструкции создания необходимых индексов для любого плана выполнения в кэше. Стоит обратить внимание на частоту выполнения запроса: чем она выше, тем более актуальными являются результаты выполнения запроса и, соответственно, собранные показатели. Если запрос выполнялся единожды, его результаты не столь показательны.

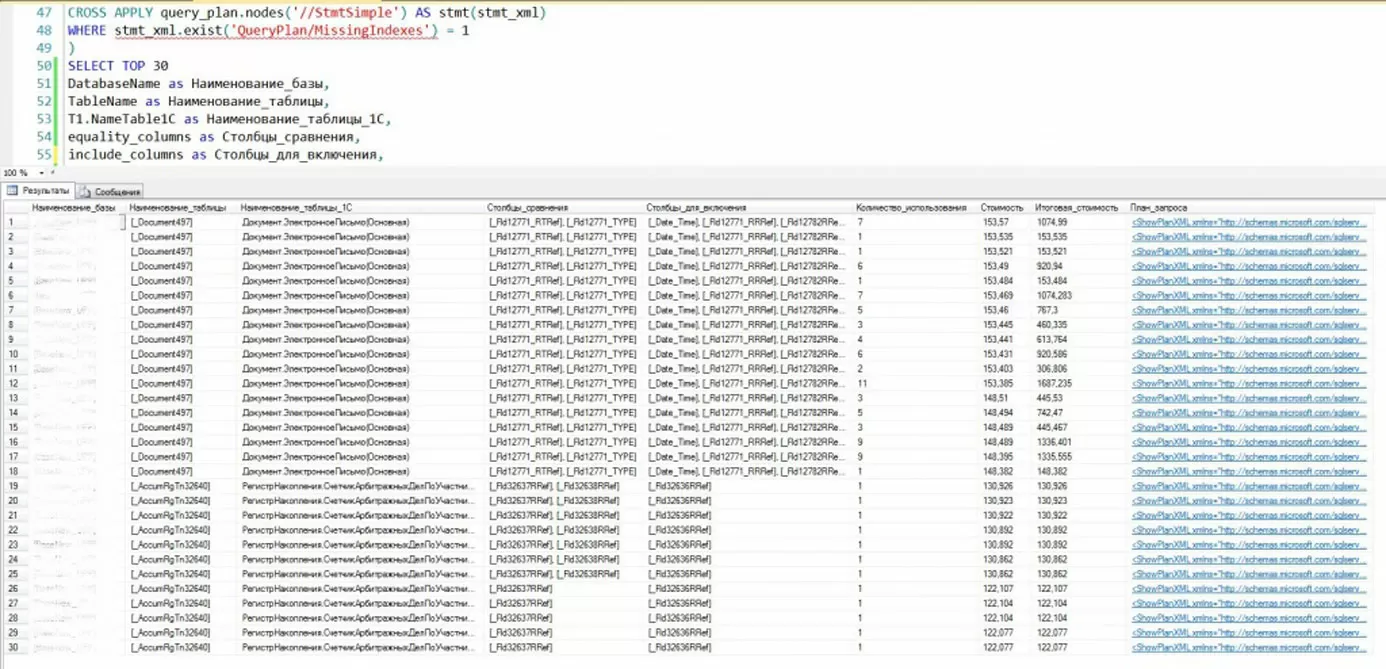
Фрагмент 8
CROSS APPLY query_plan.nodes(’//StmtSimple') AS stmt(stmt_xml)
WHERE stmt_xml.exist('QueryPlan/Missinglndexes') = 1
)
SELECT TOP 30
DatabaseName as Наименование_базы,
TableName as Наименование_таблицы,
T1.NameTable1С as Наименование_таблицы_1С,
equality_columns as Столбцы_сравнения,
include_columns as Столбцы_для_включения,
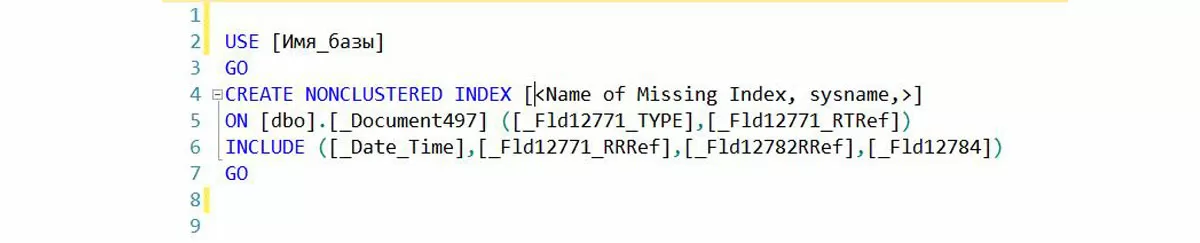
Фрагмент 9
USE [Имя_базы]
GO
CREATE NONCLUSTERED INDEX [
Создание индекса на столбцах, указанных в предложении «УПОРЯДОЧИТЬ ПО» (ORDER BY), помогает оптимизатору запроса быстро организовать результирующий набор данных, так как значения столбцов отсортированы в индексе заранее. Внутренняя реализация механизма «СГРУППИРОВАТЬ ПО» (GROUP BY) также сначала сортирует значения столбцов для быстрой группировки необходимых данных.
При использовании типовых рекомендаций стоит проверять результат до и после оптимизации. Приведем пример использования логического объединения «ИЛИ» и его альтернативы (для устранения проблемы типовыми рекомендациями) – методики изменения запроса через синтаксис «ОБЪЕДИНИТЬ ВСЕ».
Сам запрос 1С с «ИЛИ»:
ВЫБРАТЬ Код, Наименование, Ссылка
ИЗ
Справочник.Контрагенты КАК Контрагенты
ГДЕ
Контрагенты.Код = "000000004"
ИЛИ Контрагенты.Код = "0074853"
ИЛИ Контрагенты.Код = "000000024"
ИЛИ Контрагенты.Код = "009679294"
ИЛИ Контрагенты.Код = "0074742"
ИЛИ Контрагенты.Код = "000000104";
Модификация запроса с «ОБЪЕДИНИТЬ ВСЕ»:
ВЫБРАТЬ Код, Наименование, Ссылка
ИЗ
Справочник.Контрагенты КАК Контрагенты
ГДЕ
Контрагенты.Код = "000000004"
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ Код, Наименование, Ссылка
ИЗ
Справочник.Контрагенты КАК Контрагенты
ГДЕ
Контрагенты.Код = "0074853"
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ Код, Наименование, Ссылка
ИЗ
Справочник.Контрагенты КАК Контрагенты
ГДЕ
Контрагенты.Код = "000000024"
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ Код, Наименование, Ссылка
ИЗ
Справочник.Контрагенты КАК Контрагенты
ГДЕ
Фактический план запроса (для удобства отображения и сравнения производительности, запросы перехвачены и выполнены в SSMS):
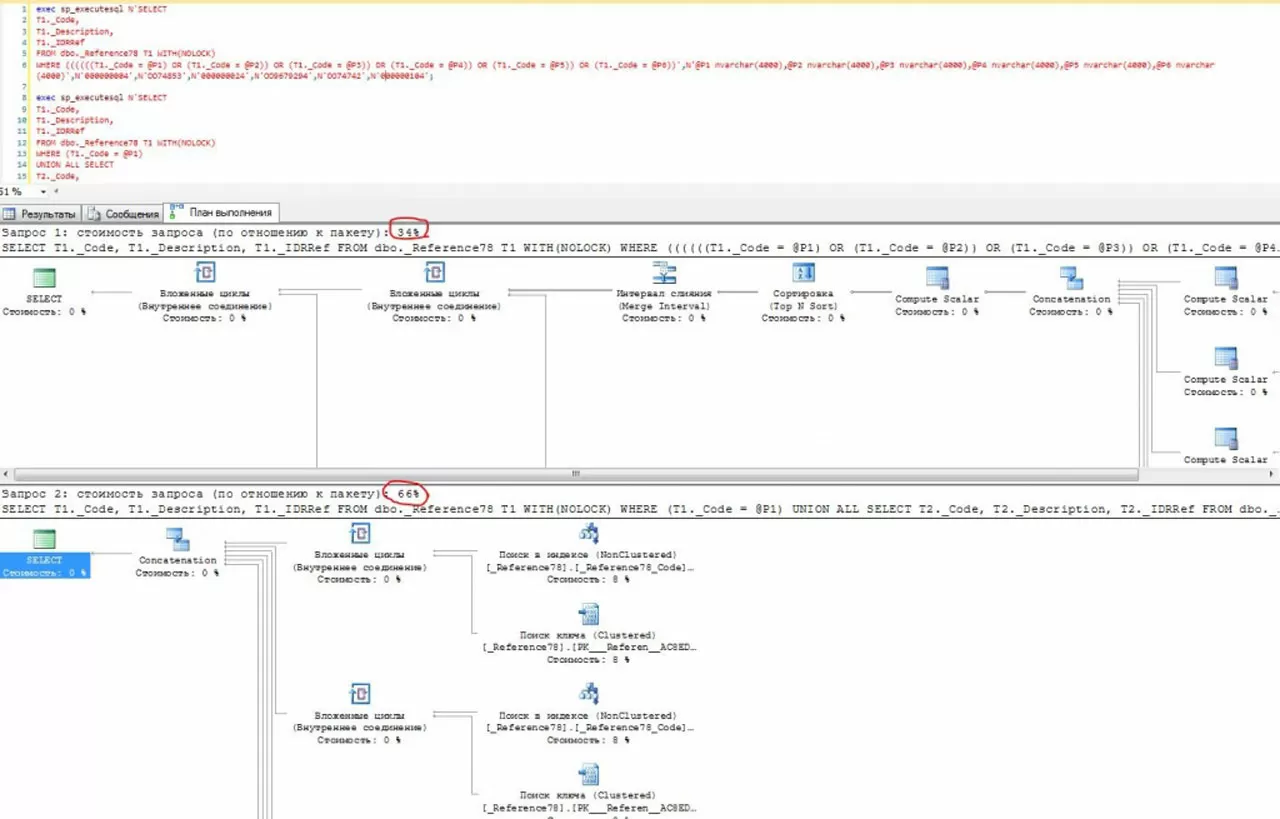
В данном случае, после оптимизации производительность упала в два раза из-за многократного использования оператора Key Lookup, который всегда сопровождается оператором Nested Loops. Поэтому, используя схему по оптимизации запроса, следует замерять целевое время до и после использования доработок. Данный пример показан с целью «доверяй, но проверяй», поскольку между типовыми рекомендациями и практическими задачами может быть несогласованность.
консультация эксперта

самые свежие новости 1 раз в месяц


